飞扬围棋
标题: 阿法零面世8小时解决1切棋类 [打印本页]
作者: lu01 时间: 2017-12-6 16:15
标题: 阿法零面世8小时解决1切棋类
[attach]140923[/attach]
作者: lu01 时间: 2017-12-6 16:15
[attach]140924[/attach]
作者: lu01 时间: 2017-12-6 16:17
[attach]140925[/attach][attach]140926[/attach]
作者: mengjin2015 时间: 2017-12-6 16:25
真服了
作者: caiyidie 时间: 2017-12-6 17:22
 ,太强大了。
,太强大了。
作者: 肥仔胡 时间: 2017-12-6 17:41
我个人认为他们的路走偏了,原来说搞这种东西主要目的是为了医疗和环保。现在解决不了医疗问题,倒在棋上较上劲了。很无聊。
作者: lu01 时间: 2017-12-6 19:04
原文 https://zhuanlan.zhihu.com/p/317 ... mp;utm_source=weibo
作者: hjagg8899 时间: 2017-12-6 19:42
希望尽快应用到医疗,教育,交通等部门
作者: lu01 时间: 2017-12-6 20:20
google翻译
摘要国际象棋博弈是人工智能史上研究最为广泛的领域。最强大的程序基于先进的搜索技术,特定领域的改编以及数十年来由人类专家改良的手工评估功能。相比之下,AlphaGo Zero计划最近在Go游戏中实现了超人的表现,白板游戏从自我游戏中获得了增强。在本文中,我们将这种方法推广到一个AlphaZero算法中,该算法可以在许多具有挑战性的领域实现tabula rasa超人的性能。从随机游戏开始,除了游戏规则,没有任何领域的知识,AlphaZero在24小时内实现了在棋类和棋类游戏中的超人类水平以及Go,并且令人信服地击败了世界冠军计划每个案例。
计算机象棋的研究和计算机科学本身一样古老。 Babbage,Turing,Shannon和von Neumann设计了硬件,算法和理论来分析和玩棋牌游戏。国际象棋随后成为一代人工智能研究者的重大挑战任务,最终形成超人类高性能计算机象棋程序(9,13)。然而,这些系统是高度调整到他们的领域,不能被推广到其他问题没有人力的重大努力。
人工智能的长期目标是创造出可以从第一原理中学习的程序(26)。最近,AlphaGo Zero算法通过使用深度卷积神经网络(22,28)表示Go知识,仅通过自我游戏(29)的强化学习来训练,从而在Go的游戏中实现了超人的表现。在本文中,我们应用了一个类似的但是完全通用的算法,我们可以使用AlphaZero,除了规则之外还有其他的领域知识证明了通用强化学习算法可以在许多具有挑战性的领域实现超白人的表现。
“深蓝”击败人类世界冠军的时候,人造智能的一个里程碑就是在1997年实现的(9)。计算机国际象棋程序在未来二十年继续稳步超越人类水平。这些程序使用人工大师手工制作的特征和仔细调整的权重来评估职位,并结合高性能的alpha-beta搜索,使用大量的巧妙启发式技术和领域特定的适应性扩展了大量的搜索树。在这些方法中,我们描述这些增强,重点是2016年顶级国际象棋引擎锦标赛(TCEC)世界冠军股票(25);其他强大的国际象棋程序,包括深蓝,使用非常相似的架构(9,21)。
在计算复杂性方面,将棋比棋(2,14)要难得多:在一个更大的棋盘上进行比赛,任何被俘获的对手棋子都会发生变化,随后可能会被丢在棋盘上的任何位置。电脑将棋协会(CSA)的世界冠军埃尔莫(Elmo)等最强大的将棋项目最近才打败了人类的冠军(5)。这些程序使用与计算机国际象棋程序类似的算法,同样基于一个高度优化的alpha-beta搜索引擎,具有许多领域特定的适应性。
Go非常适合AlphaGo中使用的神经网络架构,因为游戏规则是平移不变的(匹配卷积网络的权重共享结构),它是根据板上点之间相邻的自由度定义的卷积网络的局部结构),并且是旋转和反射对称的(允许数据增加和合成)。此外,动作空间很简单(可以在每个可能的位置放置一块石头),而且游戏结果仅限于二元输赢,这两者都可能有助于神经网络的训练。
象棋和将棋可以说并不适合AlphaGo的神经网络架构。这些规则是依赖于位置的(例如棋子可以从第二级向前移动两步,在第八级晋级)和不对称(例如棋子只向前移动,而在王牌和后侧棋子则不同)。规则包括远程互动(例如,女王可能一次性移动棋盘,或者从棋盘的远侧闯入国王)。国际象棋的行动空间包括棋盘上所有棋手的所有合法目的地;将棋也可以将被捕获的棋子放回棋盘上。国际象棋和将棋都可能造成胜负之外的胜负;事实上,相信最佳的解决方案是平局(17,20,30)。
AlphaZero算法是在Go(29)中首次引入的AlphaGo Zero算法的更通用的版本。它用深度神经网络和白板强化学习算法替代传统游戏程序中使用的手工制作的知识和特定领域的增强。
AlphaZero不是使用手工评估函数和移动排序启发式算法,而是使用具有参数的深度神经网络(p; v)= f(s)。这个神经网络以板块位置s为输入,输出一个移动概率向量p,其中对于每个动作a,分量为pa = Pr(ajs)2,标量值v根据位置s估计期望结果z,v E [ZJS]。 AlphaZero完全从自我学习这些移动概率和价值估计;这些被用来指导其搜索。
AlphaZero使用通用的蒙特卡洛树搜索(MCTS)算法,而不是具有域特定增强功能的alpha-beta搜索。每一次搜索都包含一系列模拟自我游戏的游戏,从根节点到树叶遍历一棵树。根据当前的神经网络f,通过在每个状态s中选择一个具有低访问次数,高移动概率和高值(在从s选择的模拟的叶状态上平均的值)的移动a来进行每个模拟。搜索返回一个向量,表示移动的概率分布,或者根据状态的访问次数按比例或者贪婪。
AlphaZero中的深度神经网络的参数通过自我增强学习来训练,从随机初始化参数开始。在MC上,通过选择双方玩家的动作来玩游戏。在游戏结束时,根据游戏规则对终端位置sT进行评分,以计算游戏结果z:1为损失,0为平局,+1为赢。更新神经网络参数以使预测结果vt和游戏结果z之间的误差最小化,并使策略向量pt与搜索概率t的相似性最大化。具体来说,参数是通过梯度下降在均值平方误差和交叉熵损失之和上的损失函数l进行调整的(p; v)= f(s)。 (1)其中c是控制L2权重正则化水平的参数。更新的参数被用于随后的自我游戏中。
本文描述的AlphaZero算法在几个方面与原始的AlphaGo Zero算法不同。
假设二元赢/输结果,AlphaGo Zero估计和优化获胜概率。 AlphaZero反而会估算和优化预期的结果,同时考虑平局或潜在的其他结果。
围棋的规则是不变的旋转和反射。这个事实在AlphaGo和AlphaGo Zero中有两种使用方式。首先,训练数据通过为每个位置生成8个对称来增强。其次,在MCTS期间,董事会职位在被神经网络评估之前使用随机选择的轮换或反射进行转换,以便蒙特卡罗评估在不同的偏见下进行平均。国际象棋和将棋的规则是不对称的,一般来说对称是不可能的。 AlphaZero不会增加训练数据,也不会在MCTS期间转换棋盘位置。
在AlphaGo Zero中,自我游戏是由所有以前迭代中最好的玩家生成的。在每次训练结束后,新玩家的表现与最佳玩家进行对比;如果以55%的优势获胜,那么它将取代最好的玩家,而自我游戏则是由这个新玩家产生的。相反,AlphaZero只是维护一个连续更新的单个神经网络,而不是等待迭代完成。
3图1:培训70万步AlphaZero。 Elo评级是根据不同参与者之间的评估游戏计算得出的,每次移动一秒。国际象棋中AlphaZero的表现,与2016年TCEC世界冠军计划相比较。 b在2017年CSA世界冠军项目“Elmo”中,将会在会棋中表现Al-PhaZero。 c AlphaZero在Go中的性能,与AlphaGo Lee和AlphaGo Zero(20块/ 3天)(29)相比。
自我游戏是通过使用这个神经网络的最新参数生成的,省略了评估步骤和选择最佳玩家。
AlphaGo Zero通过贝叶斯优化调整搜索的超参数。在Alp- haZero中,我们对所有游戏重复使用相同的超参数,而无需进行特定于游戏的调整。唯一的例外是为保证勘探而添加到先前政策中的噪音(29);这与该游戏类型的合法移动的典型数量成比例地缩放。
像AlphaGo Zero一样,棋盘状态仅由基于每个游戏的基本规则的空间平面编码。这些动作由空间平面或矢量编码,再次仅基于每个游戏的基本规则(参见方法)。
我们将AlphaZero算法应用于国际象棋,将棋,还有Go。除非另有说明,否则所有三种游戏都使用相同的算法设置,网络架构和超参数。我们为每场比赛训练了一个AlphaZero的独立实例。训练从随机初始参数开始,使用5,000第一代TPU(15)生成自我游戏和64个第二代TPU来训练神经网络,进行了700,000步(小批量4096)。
1方法中提供了培训程序的更多细节。
图1显示了AlphaZero在自我强化学习期间的表现,作为训练步骤的函数,在Elo量表(10)上。在国际象棋中,AlphaZero仅仅花了4个小时(300k步)跑赢了股票。在将棋之后,AlphaZero在不到2小时(110K步)之后胜过了Elmo;而在Go中,AlphaZero在8小时后(165k步)胜过AlphaGo Lee(29).
2我们在国际象棋,将棋和围棋中分别评估了AlphaZero与StockFish,Elmo和AlphaGo Zero的早期版本(训练3天)的完全训练实例,在比赛时间控制中每场比赛进行100分钟的比赛时间控制。 AlphaZero和以前的AlphaGo Zero使用一台带有4个TPU的机器。股票上涨和埃尔莫玩他们1原始的AlphaGo零报纸使用GPU来训练神经网络。
2 AlphaGo Master和AlphaGo Zero最终在这段时间内训练了100次;我们不会在这里重现这一努力。
4Game白棋黑棋棋局AlphaZero股票比赛25 25 0股票比赛sh AlphaZero 3 47 0棋将AlphaZero Elmo 43 2 5 Elmo AlphaZero 47 0 3 Go AlphaZero AG0 3天31 - 19 AG0 3天AlphaZero 29 - 21表1:锦标赛评估国际象棋,将棋和围棋中的AlphaZero,在AlphaZero的视角下赢得比赛,赢得比赛或者失去比赛,经过3天的训练后,与Stock fi sh,Elmo和之前发布的AlphaGo Zero进行了100场比赛。每个程序都有1分钟的思考时间。
使用64个线程和1GB的散列大小的最强技能水平。 AlphaZero令人信服地击败了所有的对手,丢失了0场比赛给股票和八场比赛给Elmo(见几个例子游戏的补充材料),以及击败以前版本的AlphaGo Zero(见表1)。
我们还分析了AlphaZero MCTS搜索的相对性能,与Stock fi sh和Elmo使用的最先进的alpha-beta搜索引擎相比。 AlphaZero在国际象棋中只搜索每秒8万个位置,在将棋中搜索4万个,相比之下,股票价值为7000万,Elmo则为3500万。 AlphaZero通过使用其深度神经网络更有选择地聚焦最有希望的变化,可以补偿较少的评估数量 - 可以说是像Shannon(27)最初提出的那样,是一种更像“类人”的搜索方法。图2显示了每个玩家在思考时间方面的可扩展性,以Elo量表衡量,相对于思考时间为40ms的股票或Elmo。 AlphaZero的MCTS在思考时间方面的规模要比Stockfin sh或Elmo更有效,这引起了人们广泛持有的观点(4,11),认为alpha-beta搜索在这些领域本质上是优越的。
最后,我们分析了AlphaZero发现的国际象棋知识。表2分析了最常见的人类开放(在人类国际象棋游戏(1)的在线数据库中玩过超过10万次)。在自我训练期间,AlphaZero经常独立地发现和演奏每一个这些开口。从每次人类开放开始,Alpha Zero都令人信服地击败了股票,表明它确实掌握了大量的国际象棋游戏。
象棋游戏代表了人工智能研究几十年的顶峰。最先进的程序基于强大的搜索引擎,搜索数以百万计的职位,掌握手工领域专业知识和复杂的领域适应。 AlphaZero是一个通用的强化学习算法 - 最初为Go的游戏而设计 - 在几个小时内达到了最好的结果,在没有领域的情况下搜索少了一千倍的位置3高级象棋中抽取的流行趋于压缩Elo比例,比棋将或围棋。
作者: lu01 时间: 2017-12-6 20:28
表2:分析12个最受欢迎的人类开放(在线数据库中玩过10万次以上(1))。每个开口标有其ECO代码和通用名称。该图显示了AlphaZero每次打开的自我训练比赛的训练时间比例。我们还报告了100场比赛AlphaZero的胜利/平局/失败结果
从AlphaZero的角度来看,每场比赛开始的时候都会有白色(w)或者黑色(b)。最后,从每个开口提供AlphaZero的主要变化(PV)。
图2:思维时间的AlphaZero的可扩展性,用Elo量表测量。国际象棋中的AlphaZero和股票的表现,与思考时间的一举一动。 b将棋中的AlphaZero和Elmo的表现,与每一步的思考时间作图。
除国际象棋规则以外的知识。此外,同样的算法不用修改将更具挑战性的将棋比赛,几个小时内再次胜过现有技术
计算机国际象棋程序剖析在本节中,我们将描述一个典型的计算机国际象棋程序的组成部分,重点介绍一个获得2016年TCEC计算机国际象棋锦标赛的开放源码程序--Fire fi sh(25)。有关标准方法的概述,请参阅(23)。
每个位置s由手工特征的稀疏矢量描述,包括中场/特定于终点的物质点值,物质不平衡表,棋子,流动性和被困件,棋子结构,国王安全,前哨,主教对和其他杂项评估模式。通过手动和自动调谐的组合,每个特征i被分配相应的权重wi,并且通过线性组合v(s; w)=(s)> w来评估位置。但是,对于“安静”的位置,这种原始评估仅被认为是准确的,没有未解决的捕获或检查。在应用评估函数之前,使用领域专用的静止搜索来解决正在进行的战术情况。
位置s的最终评估是通过使用静止搜索评估每片叶子的极小极大搜索来计算的。 alpha-beta修剪被用来安全地切割任何可能被另一个变体支配的分支。额外的削减是使用愿望窗口和主要的变化搜索实现的。其他修剪策略包括无效修剪(假定通过移动应该比任何变化更糟糕,在简单的启发式方法中不可能存在于zugzwang中的位置),徒劳修剪(假定知道最大可能的变化在评估中)以及其他依赖于领域的修剪规则(假定知道被捕获件的价值)。
搜索的重点是有希望的变化,既可以通过扩大有效变化的搜索深度,也可以通过基于历史,静态交换评估(SEE)和移动块类型等启发式算法来减少无用变化的搜索深度。扩展是基于域独立的规则,这些规则识别单一的移动,没有明智的选择,以及依赖于域的规则,比如扩展检查移动。减量,如后期减少,主要依赖于领域知识。
alpha-beta搜索的效率主要取决于移动的顺序。因此,移动是通过迭代加深来排序的(使用更浅的搜索命令移动以进行更深入的搜索)。此外,结合了与领域无关的移动排序启发式,如杀手启发式,历史启发式,反移动启发式,以及基于捕获(SEE)和潜在捕获(MVV / LVA)的领域相关知识。
换位表便于重复使用数值,并在多个路径达到相同位置时移动订单。经过仔细调整的开放书籍用于在游戏开始时选择移动。通过对残局位置的彻底逆向分析预先计算的残局桌基,在所有六个,有时甚至七个棋子或更少的位置提供最佳的移动。
其他强大的国际象棋程序,以及像深蓝这样的早期程序,都使用了非常类似的架构(9,23),包括上述的大部分组件,尽管10个重要细节差别很大。
AlphaZero不使用本节中描述的技术。这些技术中的一些可能会进一步提高AlphaZero的性能。然而,我们专注于纯粹的自我强化学习方法,并将这些扩展留给未来的研究。
电脑国际象棋和将棋之前的工作在本节中,我们将讨论一些关于计算机国际象棋中强化学习的重要工作。
NeuroChess(31)通过使用175个手工输入特征的神经网络来评估位置。通过时间差分学习训练,预测最终的游戏结果,以及两次移动后的预期特征。 NeuroChess使用固定的深度2搜索赢得了13%的对抗GnuChess的游戏。
Beal和Smith应用时间差异学习来估计国际象棋(7)和将棋(8)中的棋子值,从随机值开始,单独通过自我学习来学习。
KnightCap(6)通过一个神经网络来评估位置,这个神经网络使用了一个基于哪个方块受到哪些方块攻击或防守的知识的攻击表。它是由时变差异学习的一种变体(称为TD(叶))进行训练的,它更新了alpha-beta搜索的主要变化的叶子值。 KnightCap在训练强大的计算机对手后,通过手动初始化的块值权重,达到了人类主人的水平。
Meep(32)通过基于手工特征的线性评估函数来评估职位。
它是由另一个时间差异学习变种(被称为TreeStrap)训练的,它更新了一个alpha-beta搜索的所有节点。 Meep在15场比赛中13场击败了人类国际大师级球员,经过随机初始训练后进行自我训练。
Kaneko和Hoki(16)通过学习在alpha-beta选择期间学习选择专家的人体动作来训练包括一百万个特征在内的将棋评价函数的权重。他们还根据专家游戏日志规定的极小极小搜索进行大规模优化(12)。这是Bonanza引擎赢得2013年世界计算机将棋冠军的一部分。
长颈鹿(19)通过一个神经网络评估位置,包括移动性地图和攻击和捍卫描述每个正方形的最低值攻击者和防御者的地图。它通过使用TD(叶)的自我训练,也达到了与国际大师相当的游戏水平。
DeepChess(11)训练了一个神经网络来执行成对的位置评估。它是通过监督学习从人类专家游戏数据库进行培训的,这些游戏已经过滤,以避免捕捉移动和绘制游戏。 DeepChess达到了一个强大的特级玩家的水平。
所有这些计划都将学习的评估功能与各种扩展增强的alpha-beta搜索相结合。
基于使用AlphaZero-like策略迭代的双重策略和价值网络训练的方法已成功应用于改进Hex(3)中的最新技术。
11MCTS和Alpha-Beta搜索至少四十年来,最强大的计算机国际象棋程序已经使用alpha-beta搜索(18,23)。 AlphaZero使用明显不同的方法来平均子树内的位置评估,而不是计算该子树的最小最大值评估。然而,使用传统MCTS的国际象棋程序比Alpha-Beta搜索程序弱得多,(4,24);而基于神经网络的alpha-beta程序以前不能与更快的手工评估函数竞争。
AlphaZero使用基于深度神经网络的非线性函数逼近来评估位置,而不是典型国际象棋程序中使用的线性函数逼近。
这提供了一个更强大的表示,但也可能引入虚假的近似误差。 MCTS对这些近似误差进行平均,因此在评估大型子树时趋于抵消。相比之下,alpha-beta搜索计算明确的最小值,它将最大的近似误差传播到子树的根。使用MCTS可以允许AlphaZero有效地将其神经网络表示与强大的,独立于域的搜索相结合。
领域知识1.描述位置的输入特征和描述移动的输出特征被构造为一组平面;即神经网络结构与电路板的网格结构相匹配。
2. AlphaZero提供完善的游戏规则知识。这些在MCTS期间被用来模拟由一系列移动产生的位置,以确定游戏终止,并对达到终端状态的任何模拟进行评分。
3.对规则的了解也被用来编码输入平面(即castling,repeat,no-progress)和输出平面(将棋棋子如何移动,促销和落子)。
4.合法移动的典型数量用于缩放勘探噪音(见下文)。
5.超过最大棋步数(由典型游戏长度决定)的国际象棋棋将被终止,去年的比赛被终止,并与特朗普 - 泰勒规则得分,类似于以前的工作(29)。
除了上面列出的要点,AlphaZero没有使用任何形式的领域知识。
表示在本节中,我们将描述板子输入的表示,以及AlphaZero中神经网络使用的动作输出的表示。其他表示本来可以使用;在我们的实验中,训练算法对于许多合理的选择有效地工作。
作者: fyw 时间: 2017-12-6 21:26
太强大了。
作者: deepmind 时间: 2017-12-6 22:38
厉害!
作者: 天下风云 时间: 2017-12-6 23:08
怎么不试试中国象棋?
作者: stillcen 时间: 2017-12-7 08:13
问题来了,alpha zero 和alphago zero,下围棋,谁强?
目前只看到是新的zero学得快
作者: lifetimes 时间: 2017-12-7 08:42
完全信息博弈,是不完全信息博弈的子集?训练方法也许还需要一个突破,但相信不会太远
作者: hidear 时间: 2017-12-12 22:04

作者: lu01 时间: 2018-3-5 19:50
国际象棋版AlphaZero出来了 还开源了Keras实现
国际象棋版AlphaZero出来了 还开源了Keras实现
2018年03月05日 14:27 新浪体育
缩小字体 放大字体 收藏 微博 微信 分享 腾讯QQ QQ空间
<iframe name="sinaadtk_sandbox_id_0" width="640" height="90" id="sinaadtk_sandbox_id_0" src="javascript:''" frameborder="0" marginwidth="0" marginheight="0" scrolling="no" vspace="0" hspace="0" style="float: left;" allowtransparency="true">
 截图
截图
原作 @Zeta36
Root 编译自 全球最大同性交友网站
量子位 报道 | 公众号 QbitAI
只用了不到4小时。
AlphaZero在去年底通过自我对弈,就完爆上一代围棋冠军程序AlphaGo,且没有采用任何的人类经验作训练数据(至少DeepMind坚持这么认为,嗯)。
昨天,GitHub有位大神@Zeta36用Keras造出来了国际象棋版本的AlphaZero,具体操作指南如下。
项目介绍
该项目用到的资源主要有:
去年10月19号DeepMind发表的论文《不靠人类经验知识,也能学会围棋游戏》
基于DeepMind的想法,GitHub用户@mokemokechicken所做的Reversi开发,具体前往https://github.com/mokemokechicken/reversi-alpha-zero
DeepMind刚发布的AlphaZero,从零开始掌握国际象棋:https://arxiv.org/pdf/1712.01815.pdf。
之前量子位也报道过,AlphaZero仅用了4小时(30万步)就击败了国际象棋冠军程序Stockfish。是不是🐵赛雷(´・Д・)’
更多细节去wiki看呗。
笔记
我是这个信息库(repositories,也简称repo)的创造者。
这个repo,由我和其他几个小伙伴一起维护,并会尽我们所能做到最好。
repo地址:https://github.com/Zeta36/chess-alpha-zero/graphs/contributors
不过,我们发现让机器自己对弈,要烧很多钱。尽管监督学习的效果很好,但我们从来没有尝试过自我对弈。
在这里呢,我还是想提下,我们已经转移到一个新的repo,采用大多数人更习惯的AZ分布式版本的国际象棋(MCTS in C ++):https://github.com/glinscott/leela-chess
现在,项目差不多就要完成啦。
每个人都可以通过执行预编译的Windows(或Linux)应用程序来参与。这个项目呢,我们赶脚自己做得还是不错的。另外,我也很确定,在短时的分布式合作时间内,我们可以模拟出DeepMind结果。
所以呢,如果你希望能看到跑着神经网络的UCI引擎打败国际象棋冠军程序Stockfish,那我建议你去看看介个repo,然后肯定能增强你家电脑的能力。
使用环境
Python 3.6.3tensorflow-gpu: 1.3.0Keras: 2.0.8
最新结果 (在@Akababa用户的大量修改贡献后获得的)
在约10万次比赛中使用监督式学习,我训练了一个模型(7个剩余的256个滤波器块),以1200个模拟/移动来估算1200 elo。 MCTS有个优点,它计算能力非常好。
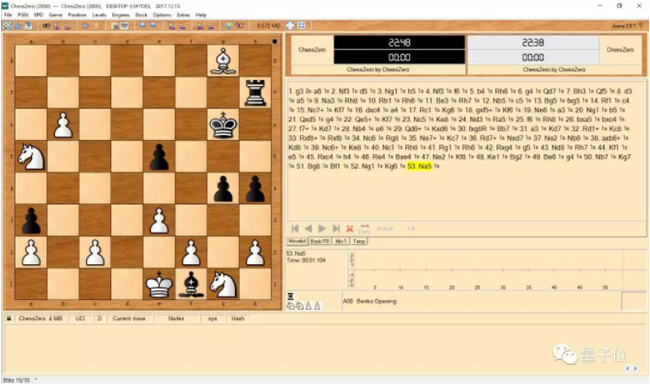
下面动图泥萌可以看到,我(黑色)在repo(白色)模型中对阵模型:

下面的图,你可以看到其中一次对战,我(白色,〜2000 elo)在repo(黑色)中与模型对战:

首个好成绩
在用了我创建的新的监督式学习步骤之后,我已经能够训练出一个看着像是国际象棋开局的学习模型了。
下图,大家可以看到这个模型的对战(AI是黑色):

下面,是一场由@ bame55训练的对战(AI玩白色):

5次迭代后,这个模型就能玩成这样了。这5次里,’eval’改变了4次最佳模型。而“opt”的损失是5.1(但结果已经相当好了)。
Modules
监督学习
我已经搞出来了一个监督学习新的流程。
从互联网上找到的那些人类游戏文件“PGN”,我们可以把它们当成游戏数据的生成器。
这个监督学习流程也被用于AlphaGo的第一个和最初版本。
考虑到国际象棋算是比较复杂的游戏,我们必须在开始自我对弈之前,先提前训练好策略模型。也就是说,自我对弈对于象棋来说还是比较难。
使用新的监督学习流程,一开始运行挺简单的。
而且,一旦模型与监督学习游戏数据足够融合,我们只需“监督学习”并启动“自我”,模型将会开始边自我对弈边改进。
python src/chess_zero/run.py sl
如果你想使用这个新的监督学习流程,你得下载一个很大的PGN文件(国际象棋文件)。
并将它们粘贴到data / play_data文件夹中。BTW,FICS是一个很好的数据源。
您也可以使用SCID程序按照玩家ELO,把对弈的结果过滤。
为了避免过度拟合,我建议使用至少3000场对战的数据集,不过不要超过3-4个运行周期。
强化学习
AlphaGo Zero实际上有三个workers:self,opt和eval。
self,自我模型,是通过使用BestModel的自我生成训练数据。opt,训练模型,是用来训练及生成下一代模型。eval是评测模型,用于评估下一代模型是否优于BestModel。如果更好,就替换BestModel。
分布式训练
现在可以通过分布式方式来训练模型。唯一需要的是使用新参数:
输入分布式:使用mini config进行测试,(参见src / chess_zero / configs / distributed.py)分布式训练时,您需要像下面这样在本地运行三方玩家:
python src/chess_zero/run.py self —type distributed (or python src/chess_zero/run.py sl —type distributed)python src/chess_zero/run.py opt —type distributedpython src/chess_zero/run.py eval —type distributed
图形用户界面(GUI)
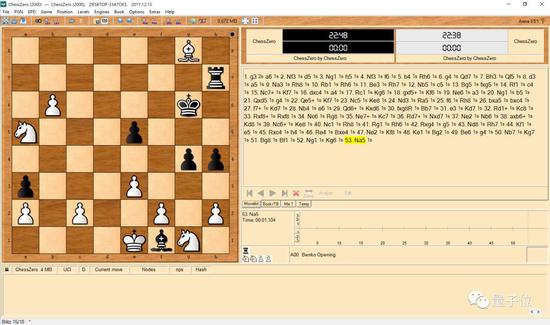
为ChessZero设置一个GUI,将其指向C0uci.bat(或重命名为。sh)。例如,这是用Arena的自我对弈功能的随机模型的屏幕截图:
数据
data/model/modelbest: BestModel。
data/model/next_generation/: next-generation models。
data/playdata/play*。json: generated training data。
logs/main.log: log file。
如果您想从头开始训练模型,请删除上述目录。
使用说明
安装
安装库
pip install -r requirements.txt
如果您想使用GPU,请按照以下说明使用pip3进行安装。
确保Keras正在使用Tensorflow,并且你有Python 3.6.3+。根据您的环境,您可能需要运行python3 / pip3而不是python / pip。
基本使用
对于训练模型,执行自我对弈模型,训练模型和评估模型。
注意:请确保您正在从此repo的顶级目录运行脚本,即python src / chess_zero / run.py opt,而不是python run.py opt。
自我对弈
python src/chess_zero/run.py self
执行时,自我对弈会开始用BestModel。如果不存在BestModel,就把创建的新的随机模型搞成BestModel。
你可以这么做
创建新的BestModel;使用mini config进行测试,(参见src / chess_zero / configs / mini.py)。
训练模型
python src/chess_zero/run.py opt
执行时,开始训练。基础模型会从最新保存的下一代模型中加载。如果不存在,就用BestModel。训练好的模型每次也会自动保存。
你可以这么做
输入mini:使用mini config进行测试,(参见src / chess_zero / configs / mini.py)用全套流程:指定整套流程的(小批量)编号,不过跑完全程会影响训练的学习率。
评价模型
python src/chess_zero/run.py eval
执行后,开始评估。它通过玩大约200场对战来评估BestModel和最新的下一代模型。如果下一代模型获胜,它将成为BestModel。
你可以这么做
输入mini: 使用mini config进行测试,(请参阅src / chess_zero / configs / mini.py)
几点小提示和内存相关知识点
GPU内存
通常来讲,缺少内存会触发警告,而不是错误。
如果发生错误,请尝试更改src / configs / mini.py中的vram_frac,
self.vram_frac = 1.0
较小的batch_size能够减少opt的内存使用量。可以尝试在MiniConfig中更改TrainerConfig#batch_size。
最后,附原文链接,https://github.com/Zeta36/chess-alpha-zero/blob/master/readme.md
— 完 —
加入社群
量子位AI社群15群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot5入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot5,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ‘ᴗ’ ի 追踪AI技术和产品新动态
关键词 : 国际象棋人工智能AlphaGo
| 欢迎光临 飞扬围棋 (http://bbs.flygo.net/Bbs/) |
Powered by Discuz! X3.2 |