飞扬围棋
标题: [轉帖]陈经:分析AlphaGo算法巨大的优势与可能的缺陷 [打印本页]
作者: cateyes 时间: 2016-3-13 17:09
标题: [轉帖]陈经:分析AlphaGo算法巨大的优势与可能的缺陷
本帖最后由 cateyes 于 2016-3-13 17:11 编辑
我覺得這篇文章寫不錯。讀研的時候用過點人工神經網絡,還有一點淺淺的印象。
http://sports.sina.com.cn/go/2016-03-13/doc-ifxqhmvc2382685.shtml
2016年03月13日12:02 观察者网
2016年3月12日人机大战第三局,AlphaGo执白176手中盘胜李世石,以3:0的比分提前取得了对人类的胜利。
这一局李世石败得最惨,早早就被AlphaGo妙手击溃,整盘毫无机会。最后李世石悲壮地造劫,在AlphaGo脱先之后终于造出了紧劫。但AlphaGo只靠本身劫就赢得了劫争,粉碎了AlphaGo不会打劫的猜想。这一局AlphaGo表现出的水平是三局中最高的,几乎没有一手棋能被人置疑的,全是好招。三局过去,AlphaGo到底实力高到什么程度,人们反而更不清楚了。
看完这三局,棋界终于差不多绝望了,原以为5:0的,都倒向0:5了。有些职业棋手在盘算让先、让二子是否顶得住。整个历程可以和科幻小说《三体》中的黑暗战役类比,人类开始对战胜三体人信心满满,一心想旁观5:0的大胜。一场战斗下来人类舰队全灭,全体陷入了0:5的悲观失望情绪中。
我也是纠结了一阵子,看着人类在围棋上被机器碾压的心情确实不好。但是承认机器的优势后,迅速完成了心理建设,又开心地看待围棋了。其实挺容易的,国际象棋界早就有这样的事了。这个可以等五盘棋过后写。
现在我的感觉是,棋界整体还是对AlphaGo的算法以及风格很不适应。一开始轻视,一输再输,姿态越来越低,三盘过后已经降到一个很低迷沉郁的心理状态了。这也可以理解,我一个围棋迷都抑郁了一会,何况是视棋如生命的职业棋手。但是不管如何,还是应该从技术的角度平心静气地搞清楚,AlphaGo到底是怎么下棋的,优势到底在哪些,是不是就没有一点弱点了?
现在有了三盘高水平的棋谱,质量远高于之前和樊麾的五盘棋谱。还有谷歌2016年1月28号发表在《自然》上的论文,介绍了很多技术细节,还有一些流传的消息,其实相关的信息并不少,可以作出一些技术分析了。
之前一篇文章提到,从研发的角度看,谷歌团队把15-20个专家凑在了一起,又提供了巨量的高性能计算资源,建立起了整个AlphaGo算法研究的“流水线”。这样谷歌团队就从改程序代码的麻烦工作中解放出来,变成指挥机器干活,开动流水线不断学习进步,改善策略网络价值网络的系数。而且这个研发架构似乎没有什么严重的瓶颈,可以持续不断地自我提升,有小瓶颈也可以想办法再改训练方法。就算它终于遇到了瓶颈,可能水平也远远超过人类了。
这些复杂而不断变动的神经网络系数是AlphaGo的独门绝技,要训练这些网络,需要比分布式版本对局时1200多个CPU多得多的计算资源。AlphaGo算法里还是有一些模块代码是需要人去写的,这些代码可不是机器训练出来的,再怎么训练也改不了,谷歌团队还不可能做到这么厉害。例如蒙特卡洛搜索(MCTS)整个框架的代码,例如快速走子网络的代码。这里其实有两位论文共同第一作者David Silver和Aja Huang多年积累的贡献。这些人写的代码,就会有内在的缺陷,不太可能是完美无缺的。这些缺陷不是“流水线”不眠不休疯狂训练能解决的,是AlphaGo真正的内在缺陷,是深度学习、self-play、进化、强化学习这些高级名词解决不了的。谷歌再能堆硬件,也解决不了,还得人去改代码。
第一局开局前,谷歌就说其实还在忙着换版本,最新版本不稳定,所以就用上一个固定版本了。这种开发工作,有可能就是人工改代码消除bug的,可能测试没完,不敢用。
总之,像AlphaGo这么大一个软件,从算法角度看存在bug是非常可能的。在行棋时表现出来就是,它突然下出一些不好的招数,而且不是因为策略网络价值网络水平不够高,而是MCTS框架相关的搜索代码运行的结果。如果要找AlphaGo潜在的bug,需要去仔细研究它的“搜索 ”。这可能是它唯一的命门所在,而且不好改进。
那么MCTS的好处坏处到底是什么?幸运的是,Zen和CrazyStone等上一代程序,以及facebook田渊栋博士开发的Darkforest都用了MCTS。它们和AlphaGo虽然棋力相差很远,但是行棋思想其实很相似,相通之处远比我们想象的高得多。
[attach]112492[/attach]
[attach]112493[/attach]
这是田渊栋贴的Darkforest对前两局的局势评分。可以看出,这个评分和棋局走向高度一致,完全说得通。而且谷歌也透露了AlphaGo对局势的评分,虽然一直领先,但第二局也有接近的时候,能够相互印证。如果到网上下载一个Zen,输入AlphaGo和李世石的对局,选择一个局面进行分析,也会有像模像样的评分出来。这究竟是怎么回事?
从技术上来说,所谓的局势评分,就是程序的MCTS模块,对模拟的合理局面的胜率估计。连AlphaGo也是这样做的,所以几个程序才能对同样一个局面聊到一块去。所有程序的MCTS,都是从当前局面,选择一些分支节点搜索,一直分支下去到某层的“叶子”节点,比如深入20步。
这个分支策略,AlphaGo和Darkforest用的是“策略网络”提供的选点,选概率大的先试,又鼓励没试过的走走。到了叶子节点后,就改用一个“快速走子策略”一直下完,不分支了,你一步我一步往下推进,比如再下200步下完数子定出胜负。这个走子策略必须是快速的,谷歌论文中说AlphaGo的快速走子策略比策略网络快1000倍。如果用策略网络来走子,那就没有时间下完了,和李世石对局时的2小时会远远不够用。下完以后,将结果一路返回,作一些标记。最后统计所有合理的最终局面,看双方胜利的各占多少,就有一个胜率报出来,作为局势的评分。一般到80%这类的胜率就没意义了,必胜了,机器看自己低于20%就中盘认输了。
AlphaGo的创新是有价值网络,评估叶子节点时不是只看下完的结果,而是一半一半,也考虑价值网络直接对叶子节点预测的胜负结果。走子选择就简单了,选获胜概率最大的那个分支。机器也会随机下,因为有时几个分支胜率一样。
MCTS这个框架对棋力最大的意义,我认为就是“大局观”好。无论局部如何激烈战斗,所有的模拟都永远下完,全盘算子的个数。这样对于自己有多少占地盘的潜力,就比毛估估要清楚多了。以前的程序,就不下到终局,用一些棋块形状幅射之类的来算自己影响的地盘,估得很差,因为一些棋块死没死都不清楚。MCTS就不错,下到终局死没死一清二楚。MCTS也不会只盯着局部得失,而是整个盘面都去划清楚边界。这个特点让几个AI对局势的评估经常很相似,大局观都不错。MCTS对于双方交界的地方,以及虚虚实实的阵势,通过打入之类的模拟,大致有个评估。当然这不是棋力的关键,大局观再好,局部被对手杀死也没有用,可能几手下来,局势评估就发生了突变。
AlphaGo的大局观还特别好,特别准确,主要是它模拟的次数最多,模拟的质量最好。而且这个大局观从原理上就超过了人类!比如人看到一块阵势,如果不是基本封闭的实空,到底价值多少评估起来其实是非常粗的。高手点目时经常这样,先把能点的目算清楚,有一些小阵势如无忧角就给个经验目数,然后加上贴目算双方精确目数的差值,然后说某方的某片阵势能不能补回这个差值,需要扣除对方打入成的目数,孤棋薄棋减目数。这类估算有很多不精确的因素。
AlphaGo就不一样了,它会真的打入到阵势里,来回模拟个几十万次,每一次都是精确的!人绝对没有能力像AlphaGo这么想问题,一定是利用经验去估算阵势的价值,误差就可能很大。极端情况下,一块空有没有棋,职业棋手根本判断不清,AlphaGo却可以通过实践模拟清楚,没棋和有棋相比,目数差别太大了。AlphaGo虽然不是严格证明,但通过概率性地多次打入模拟,能够接近理论情况,比人类凭经验要强太多了。我可以肯定,AlphaGo的大局观会远远超过职业高手,算目也要准得多,所以布局好、中后盘收束也很强大。甚至Zen之类的程序大局观都可能超过职业高手。
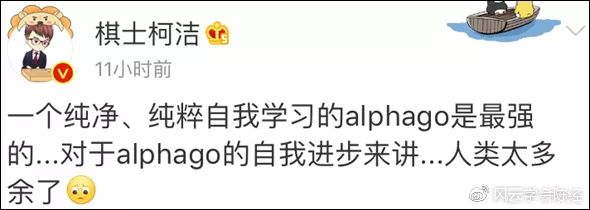
例如第二局这个局面:
[attach]112494[/attach]
李世石左下占了便宜,本来局势还可以。但是他70和72手吃了一子落了后手,被AlphaGo走到73,大局一下就落后了。这个在前面Darkforest对局势的评估图中都非常清楚,是局势的转折点。李世石要是手头有个Zen辅助,试着下两下都可能会知道70手不要去吃一子了。大局观不太好的职业高手,比如李世石就是个典型,大局观不如Zen真不一定是笑话。李世石比Zen强的是接触战全局战的手段,要强太多了。MCTS实事求是不怕麻烦下完再算子的风格,比起人类棋手对于阵势价值的粗放估算,是思维上先天的优势。
AlphaGo比其它程序强,甚至比职业高手还强的,是近身搏杀时的小手段。
[attach]112497[/attach]
第三局,李世石29和31是失着。29凑白30双,虽然获得了H17的先手,但是中间的头更为重要。当黑31手飞出后,白32象步飞可以说直接将黑击毙了。在盘面的左上中间焦点处,AlphaGo的快速走子网络会有一个7*7之类的小窗口,对这里进行穷举一样的搜索,用人手写的代码加上策略网络。32这步妙招可能就是这样找出来的,李世石肯定没有算到。但是AlphaGo是不怕麻烦的,就一直对着这里算,比人更容易看到黑三子的可怜结局。这个计算对人有些复杂,只有实力很强的才能想到算清楚,对AlphaGo就是小菜。李世石一招不慎就被技术性击倒了。AlphaGo对这种封闭局部的计算,是它超过人类的强项。
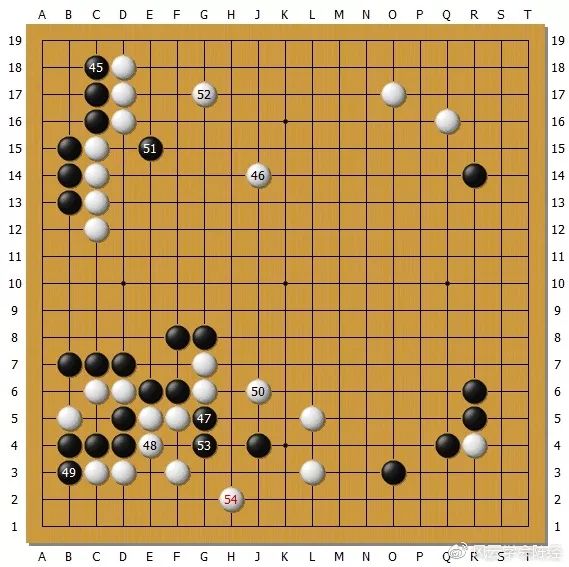
但是AlphaGo的搜索是不是就天衣无缝了?并不是。来看第二局这个局面:
[attach]112496[/attach]
AlphaGo黑41手尖冲,43手接出作战。最后下成这样,这是三局中AlphaGo被众多职业棋手一致认为最明显的一次亏损失误,如果它还有失误的话。我们猜想它为什么会失误。关键在于,这里是一个开放式的接触战,棋块会发展到很远的地方去。AlphaGo的小窗口封闭穷举搜索就不管用了,就只有靠MCTS在那概率性地试。这里分支很多,甚至有一个复杂的到达右上角的回头征。我认为AlphaGo这里就失去了可靠的技术手段,终于在这个人类一目了然的局面中迷失了。它是没有概念推理的,不知道什么叫“凭空生出一块孤棋”。也不确定人会在50位断然反击,可能花了大量时间在算人妥协的美好局面。
[attach]112495[/attach]
再来看AlphaGo一个明确的亏损。第一局白AlphaGo第136手吃掉三子。这里是一个封闭局面,是可以完全算清楚的。可以绝对地证明,136手吃在T15更好,这里白亏了一目。但是为什么AlphaGo下错了?因为它没有“亏一目”的这种概念。只有最终模拟收完数子,白是179还是180这种概念,它根本搞不清楚差的一个子,是因为哪一手下得不同产生的,反正都是胜,它不在乎胜多少。除非是176与177子的区别,一个胜一个负,那136就在胜率上劣于T15了,它可能就改下T15了。
这个局面白已经胜定了所以无所谓。但是我们可以推想,如果在对局早期,局部发生了白要吃子的选择,一种是A位吃,一种是B位吃,有目数差别,选哪种吃法?这就说不清了。AlphaGo的小窗口穷举,是为了保证对杀的胜利,不杀就输了。但是都能吃的情况下,这种一两目的区别,它还真不好编程说明。说不定就会下错亏目了。
经过以上的分析,AlphaGo相对人类的优势和潜在缺陷就清楚多了。它的大局观天生比人强得多,因为有强大的计算资源保证模拟的终局数量足够,策略网络和价值网络剪枝又保证了模拟的质量。它在封闭局部的对杀会用一个小窗口去穷举,绝对不会输,还能找到妙手。它布局好,中盘战斗控制力强,都是大局观好的表现。它中后盘收束差不多都是封闭局面了,基本是穷举了,算目非常精确,几百万次模拟下来什么都算清了。想要收官中捞点目回去不是问题,它胜了就行;但是想收官逆转是不可能的,影响了胜率它立刻就穷举把你堵回去。
但是封闭式局面的小手段中,AlphaGo可能存在不精确亏目的可能性,不知道怎么推理。在开放式接触战中,如果战斗会搞到很远去,它也可能手数太多算不清,露出破绽。但不会是崩溃性的破绽,要崩溃了它就肯定能知道这里亏了,不崩吃点暗亏它就可能糊涂着。目前来看,就是这么两个小毛病。
另外还有打劫的问题。如果是终局打劫,那是没有用的,它就穷举了,你没有办法。如果是在开局或者中局封闭式局部有了劫争,由于要找劫,等于强制变成了杀到全盘的开放度最大的开放式局面了。这是AlphaGo不喜欢的,它的小窗口搜索就用不上了。而用MCTS搜索,打劫步数过多,就会超过它的叶子节点扩展深度,比如20步就不行了,必须“快速走子”收完了。这时它就胡乱终局了,不知道如何处理劫争,模拟质量迅速下降。所以,这三局中,AlphaGo都显得“不喜欢打劫”。但是,这不是说它不会打劫,真要逼得它不打劫必输了,那它也就被MCTS逼得去打了。如果劫争发生在早中期手数很多,在打劫过程中它就可能发生失误。
当然这只是一个猜想。它利用强大的大局观与局部手段,可以做到“我不喜欢打劫,打劫的变化我绕过”,想吃就给你,我到别的地方捞回来。当然如果对手足够强大,是可以逼得它走上打劫的道路的,它就只好打了,说不定对手就有机会了。第三局李世石就逼得它打起了劫,但是变化简单它不怕,只用本身劫就打爆了对手。
如果要战胜AlphaGo,根据本文的分析,应该用这样的策略:大局观要顶得住,不能早早被它控制住了。局部手段小心,不要中招。顶住以后,在开放式的接触战中等它自己犯昏。或者在局部定型中看它自己亏目。在接触战中,要利用它“不喜欢打劫”的特性,利用一些劫争的分枝虚张声势逼它让步,但又不能太过分把它逼入对人类不利的劫争中。这么看,这个难度还真挺高的。但也不是不可想象了,柯洁大局观好,比较合适。李世石大局观差,不是好的人类代表。
本文进行了大胆的猜测,可能是一家之言。但我也是有根据的,并不是狂想。如果这篇文章能帮助人类消除对AlphaGo的恐惧,那就起到了作用。
作者简介:笔名陈经,香港科技大学计算机科学硕士,中国科学技术大学科技与战略风云学会研究员,棋力新浪围棋6D。21世纪初开始有独特原创性的经济研究。2003年的《经济版图中的发展中国家》预言中国将不断产业升级,挑战发达国家。2006年著有《中国的“官办经济”》。
致谢:感谢中国科学技术大学科技与战略风云学会会长袁岚峰博士(@中科大胡不归 )与其他会员的宝贵意见。
(观察者网)
作者: cateyes 时间: 2016-3-16 09:02
順便也轉介微軟人工智能專家的看法。
http://sports.sina.com.cn/go/2016-03-14/doc-ifxqhmve9169947.shtml
微软专家评AlphaGo:处弱人工智能阶段 离AI还很远
2016年03月14日16:00
随着人机大战这几天AlphaGo的亮眼表现,媒体的风向开始对AI的评论一边倒,Wired撰文表示《人类棋类智慧的最后一块堡垒被攻破》,Slashdot撰文表示《真正的AI已经不远了》,但最近hunch上,一位微软专家在其博客上称,也许事实完全不是这样的。
“以Go本身为例,它应用的蒙特卡洛树搜索法在Go身上异常有效,但用到其它棋类游戏就没有这么明显的作用了。
而全球经典的机器学习算法,有确定型决策过程和马尔科夫决策过程以及其它决策过程,但它们一直没被广泛运用,是因为它们是基于表格式学习而不是函数拟合,所以我们转向了 Contextual Bandit的研究,但是就算是语境决策过程,我们都还只学了一点点,跟实际运用还差地挺远的。”
另外,前几天,微软亚洲研究院芮勇也表示,总体上看,目前的人工智能产品都还处于弱人工智能阶段。目前人类只是在语音识别、语音合成、计算机视觉等方面做得比较不错,但采用的还是监督式的学习训练方式。如果计算机能够建立在非监督式的学习,那么将会开启另一个时代。(宗仁)
作者: cateyes 时间: 2016-3-16 09:04
本帖最后由 cateyes 于 2016-3-16 09:05 编辑
這個也很有意思。
http://digi.tech.qq.com/a/20160313/016046.htm
AI专家:AlphaGo缺少人类智能的一个关键元素
腾讯数码[微博] 肖恩2016年03月13日09:12
[摘要]当今许多强大的人工智能程序却没有目标,只能在人工辅助下学习事物。
腾讯数码讯(肖恩)在第三次击败当今最优秀围棋选手之一的李世石之后,谷歌的AlphaGo显然已经创造了历史。但人工智能需要多久可以达到人类的智力水平呢?对此,专家们的表达了自己的看法。
“史无前例”的功绩
人工智能及计算机科学家Richard Sutton认为,AlphaGo所取得的成就——以及自我改进的速度——都是“史无前例的”。IBM的深蓝花了至少10年时间才具备击败国际象棋世界冠军Garry Kasparov的能力。对比之下,AlphaGo从业余水平到击败世界冠军用了不到1年时间。
和国际象棋相比,围棋的变化要多得多。即便是对于今天的计算机而言,进行计算和分析也绝非易事。如此一拉,AlphaGo的成就就更让人刮目相看了。
Sutton认为,AlphaGo的成功主要得益于以下两种强大技术的结合:
1.蒙特卡洛树搜索:随机选择落子点,然后模拟整盘棋以寻找胜利策略
2.深度强化学习:一个模拟大脑连接的多层神经网络,当中包括选择下一个落子点的“策略网络”,以及预测获胜者的“价值网络”
但如果跳出围棋来看,Sutton表示,AlphaGo依然缺乏一个关键性的元素:了解世界运转方式的能力——比如理解物理定律和个人行为所导致的结果。
缺失的一环
智能系统可以被定义为能够设立并达成目标的东西。当今许多强大的人工智能程序却没有目标,只能在人工辅助下学习事物。对比之下,DeepMind的AlphaGo的确有一个目标——赢得围棋比赛——也可通过自己跟自己下棋来独立学习。
但是,围棋这种棋类运动都有一套明确的规则,因此AlphaGo可以遵守这些规则来达成目标。“但在现实世界当中,我们可没有游戏规则(可以遵守),也无法知道自身行为的后果。”Sutton说。
即便如此,Sutton并不认为开发出接近人类水平的人工智能是件遥不可及的事。
“我们有50%的几率能在2040年实现(人类水平的)智能——提前10年也不是不可能。”他说。
其他专家也认为人工智能的发展速度要比我们预料的更快。加州大学伯克利分校计算机科学教授、人工智能专家Stuart Russell认为,人工智能在许多领域里都展现出了大幅度的进步,而这个发展速度似乎还会越变越快。
但这并不是我们对人工智能心存恐惧的理由。“我并不认为人们应该害怕,”Sutton说道,“但我们的确应该去留意(人工智能的发展)。”
作者: cateyes 时间: 2016-3-20 08:12
本帖最后由 cateyes 于 2016-3-20 08:12 编辑
黃士傑提到的一些看法
http://sports.sina.com.cn/go/2016-03-18/doc-ifxqnski7725894.shtml
黄士杰揭阿尔法获胜关键 判断优势及最佳棋路2016年03月18日17:35
文/记者谭伟晟
据自由日报消息,作为人工智能开发的新里程碑,Google旗下DeepMind团队所开发的AlphaGo系统,在最近一场与世界棋王顶尖对决中,最终以4比1拿下胜利,并且荣登世界棋士排行榜第二名的位置。这场让世人见证到人工智能的高速发展的赛事,也让幕后开发AlphaGo的DeepMind团队立时成为受瞩目对象。其中来自台湾的DeepMind成员、同时也是代AlphaGo在棋盘上落子的黄士杰,今天亲临Google台湾,要来分享AlphaGo的致胜关键!
来自台湾的黄士杰,目前是Google旗下DeepMind团队的资深研究员,也是AlphaGo人工智能系统的重要开发者。而能够成为AlphaGo的关键人物。曾经开发过围棋人工智能、做过围棋老师的他,认为围棋是相当适合AI人工智能的挑战,特别是在深蓝在1997年击败人类后,围棋成为AI人工智能仍未取胜的领域。
其中AlphaGo之所以能获胜,最主要的原因在于可以‘判断优势’、‘以及取得最佳的棋路’两大要素,透过学习人类千年来智慧的结晶,学习大量的棋谱与棋路,因此可以拥有类似人类的‘直觉’下法,无须穷举运算所有的棋路,就可以决定哪一个落子处,最有机会获的胜利。
其中黄士杰表示,‘直觉’是围棋比赛中最重要的关键,职业棋士总会有神来一着,但他们也无从说起判断为何。黄士杰指出,这就是‘直觉’的重要性,透过优先找出更有优势、胜率更高的棋路,让计算机不必穷尽所有棋路可能,而可以选择最有胜率的20步,以采取胜率最高的策略。
黄士杰提到,由于围棋的变化有10的170次方,若是想要把所有的棋路穷尽思量,那么几亿年也无法运算完。因此AlphaGo采取可以判断优势的‘策略网络’,辅以可以推断棋路的‘价值网络’,让AlphaGo能拥有类似人类的直觉,以便在围棋这类复杂的棋类运动中,与人类对弈、进一步取得胜利!
黄士杰表示,在1990年时,人工智能还无法做到与人类较量围棋的能力,当时尽管让AI先下25个棋子,但仍会在最后全部被吃光落败。时至今日透过Google机器学习技术的帮助,AI的发展已经突飞猛进,在这次与李世石的对弈中,甚至获得5战4胜的成绩。
不过回顾比赛当时、坐在李世石对面的黄士杰,其实是抱着相当尊敬的心情与李世石对弈。包含避免喝水、离席、以及过多的脸部表情,都是基于尊敬李世石、不想要干扰他的比赛而产生的行为,这更让赛后李世石提到,与他对弈的黄士杰有着职业棋手的气势。黄士杰表示,在赛中他可能只有意外地笑了一次,而那次是因为李世石击败了AlphaGo,他由衷为李世石感到开心的笑容。
然而面对李世石在第四局的78手落子,为何最终会导致AlphaGo的误判、导致这个人工智能最后选择投降,黄士杰表示这确实可能是AlphaGo的BUG,但目前还不清楚是策略网络的误判、还是价值网络提供了错误的讯息,DeepMind团队还在研究导致战败的原因。
说到战败,黄士杰提到其实AlphaGo只要觉得‘没希望了’,就会主动投降,也就是在胜率低于20%的情况下,系统会弹出投降窗口,也就是在第四战大家看到的画面。但这并非意味着AlphaGo有办法事前预测和李世石对弈时,可能获胜的机率有多少。黄士杰强调,AlphaGo的胜率判断,必须基于和对方正式交手后才能判断,因此在还没比赛前,AlphaGo自己也不知道获胜的机会有多大。
而这种判断机制,也让AlphaGo在第五战成功逆转胜。除了因为学习了李世石在前四战的棋路外,先前透过两个AlphaGo系统的自主对弈训练,也是让这个人工智能系统有着超越人类围棋能力的关键。
未来AlphaGo有机会应用在其他领域上,特别是医疗领域,DeepMind已经有团队特别在进行这方面的项目。但对于人工智能不断发展,是否会出现类似‘天网’的人工智能威胁?黄士杰强调,人工智能的使用依旧取决于人类如何使用,而DeepMind团队也相当重视这个问题,Google内部甚至有伦理委员会,来决定科技的使用方式是否正确。
至于AlphaGo未来会不会挑战其他项目,像是《星际争霸》这类的实时战略游戏?黄士杰认为短时间内不可能,主要原因是实时战略游戏不同围棋,他有太多不确定的因素,对于人工智能而言还太过困难。他特别指出,人工智能目前仍是早期阶段,还没有办法创造出主动式的意识,因此未来还有很长的路要走。
作者: 温良恭俭让 时间: 2016-3-20 15:31
科普了,谢谢
作者: cateyes 时间: 2016-3-24 17:41
本帖最后由 cateyes 于 2016-3-24 17:52 编辑
http://tech.ifeng.com/a/20160309/41560469_0.shtml
原标题:专访脸书围棋项目负责人:谷歌围棋做得很好,但算法并无新意
2016年03月09日 07:04 来源:澎湃新闻 作者:孙远
在Facebook内部,判断一个项目的重要程度,有一种很直观的方法:看看这个项目的负责人离扎克伯格的办公桌有多远。
田渊栋在Facebook的办公桌离CEO扎克伯格只有6米远(20英尺),他的前排坐着的是Facebook的COO谢丽尔·桑德伯格(Sheryl Sandberg)。这样的座位安排,一开始让这个围棋项目负责人觉得有点小慌,但这足以凸显这一人工智能项目在Facebook公司中的重要性。
从美国卡耐基梅隆大学机器人学院取得博士学位后,这位来自上海的田渊栋加入谷歌无人车项目,随后跳槽到Facebook人工智能实验室。田渊栋的个人简历丰富多彩,最近,他的围棋对弈项目更是得到了扎克伯克的公开点名表扬。
因为喜欢科幻小说《三体》,来自上海的小伙子将自己的围棋对弈项目命名为黑暗森林(DarkForest)。在谷歌AlphaGo战胜欧洲冠军樊麾,引爆全球关注人机对弈的人工智能前,这个项目在Facebook人工智能实验室里低调而神秘。
“这个项目是从去年5月开始,两个人,在不到半年的时间里,虎口拔牙似得抓到一些进展,已是十分不易,任何一个地方只要动作慢了点,都不会有现在的成果。能被小扎点名我是始料未及,我感到非常荣幸。”田渊栋在接受澎湃新闻(www.thepaper.cn)专访时表示。
就在3月9日,谷歌AlphaGo将对韩国围棋冠军李世石发起挑战,展开5局的对决。作为谷歌AlphaGo的竞争对手,田渊栋没有正面回答澎湃新闻提出的是否看好谷歌获胜的问题,但他表示谷歌的人工智能确实做得很好,自己也很期待比赛。
谷歌DeepMind创始人之一丹米斯·哈撒比斯则对自己的人工智能充满信心,他曾在赛前透露说:“骗招对付不了‘阿尔法’。它现在正以无数的棋谱数据为基础进行‘深度学习’,不断地完善自己,并通过自我模拟对局提高实力。此外,电脑超强的学习能力是人脑无法比拟的,‘阿尔法’现在已学习了相当于人类1000年的学习量,所以它这几个月的棋力已得到了显著提高。”
据国外媒体报道,谷歌公司目前正用两台超级计算机模拟人类实战,每天的对局量上百盘,每盘棋的计算机投入成本大约为300美元,此外研发团队还对围棋软件有针对性地进行了很多测试。有专家认为,与去年10月的“阿尔法围棋”软件相比,今年3月版的“阿尔法围棋”经过这五个月时间的强化与完善,肯定已产生巨大的飞跃,李世石所面对的将是另外一只“猛兽”。
作为先后在谷歌和Facebook工作的研究员,田渊栋非常清楚两个科技公司在人工智能领域的各自优势。在采访中,他更是分析了两者之间的差距。
在开赛前,先听听竞争对手的分析,或许更容易理解明天的比赛。
被扎克伯格点赞始料未及,我感到非常荣幸
2013年底,著名人工智能学者、纽约大学教授在YannLeCun在自己的个人社交网站上宣布受聘于Facebook,成立人工智能研究实验室,致力于“宏大长远的目标,要给人工智能带来重大突破”。至此开始,在Yann LeCun的带领下,Facebook在人工智能领域里招兵买马,扩充实力。
田渊栋称,进入Facebook后,自己手上有七八个研究项目,DarkForest还是其中最不起眼的一个。
“到去年8月份左右,我们走子网络的性能已经超过了谷歌DeepMind在2014年底发表的文章的水平。今年一月底谷歌文章出来后,以20人一年半的团队和完美的公关,让全世界开始关注围棋。但DarkFores,靠两个人花半年时间,虎口拔牙抓到一些进展,已是十分不易,任何一个地方动作稍慢一点,都不会有现在的成果。”田渊栋说。
澎湃新闻:谷歌有alphaGo项目,我们知道Facebook也有针对棋类对弈的darkforest项目,作为这个项目的负责人,扎克伯格也曾点名表扬你的工作成果,你能否简单介绍自己在做的工作?
田渊栋:这个项目是去年5月开始的,当时我刚加入Facebook AI,开了七八个研究项目,这是其中不很起眼的一个。一开始我也不是很看好,只是为了实验一个想法而收集了下数据。后来这个想法没做出来,但是既然有数据有平台了,还不如继续做下去。当时第二作者朱岩在我们组实习,他手上的另一个项目刚结束,我就问他是不是有兴趣,他觉得挺有意思的就开始合作了。
到去年8月份左右,我们走子网络的性能已经超过了谷歌DeepMind在2014年底发表的文章的水平。于是我就把代码重新写了一遍(之前是用各种开源程序拼凑起来的),开始搭建我们自己的系统,同时把现有的走子网络放在KGS(世界上最大的围棋服务器之一,一般任何时刻同时有超过一千五百人在线)上开始和别人对战,DarkForest这个名字就是那时候起的。
去年9月份,我尝试了预测下3步而非下1步的方案,看到性能一直在提高,这时我觉得深度神经网络加上蒙特卡罗树搜索,可能会得到很不错的围棋程序。到10月份基本上蒙特卡罗树搜索的框架有了,但是还有很多bug,因为另一个项目(基于图片的问答系统)的时间吃紧,花在围棋上的时间不多。到11月份问答系统差不多了,我再回过头来做围棋,我们当时的计划是再慢慢做做准备投稿2016年2月份的ICML(国际机器学习大会),后来讨论了一下,决定还是试一试15年11月中旬的ICLR(国际机器人顶级会议)。这时候离ICLR的截稿日期还有三周。这三周加班加点,如期得到了一个还不错的系统,投了ICLR,文章放在arXiv(由美国国家科学基金会和美国能源部资助,在美国洛斯阿拉莫斯国家实验室建立的电子预印本文献库,始建于1991年8月)上公开了。
大家也知道了Facebook在做围棋。国外的ComputerGo(计算机围棋对战)论坛一开始不相信我们的程序不经盘面搜索到3段,后来因为我们在网上放久了,打定段战确实能到3段,才渐渐服众,各种媒体报道也纷至沓来。现在看起来,我们做的工作吹响了这一波围棋AI突破的号角。
之后就是继续改进蒙特卡罗树搜索,另外,组里一位工程师Tudor Bosman花了一周把我们的程序改成了分布式,到12月底,我们在KGS上到了5段的水平,很多人找我们下棋,包括最强大脑鲍云和一位韩国的职业选手,我们也在继续改进。当时已经有传言说谷歌战胜了职业选手,不过我们还是尽力而为。一月份KGS的比赛我们因为有个bug超时拿了第三名,不然是可以胜Zen拿第一的。最后一月底谷歌的文章出来,以20人一年半的团队和完美的公关,让全世界开始关注围棋,也确证了之前的传言。而我们投稿ICLR的文章也中稿了。总的来说,这个项目还是比较成功的。这次我们能两个人花半年时间,虎口拔牙抓到一些进展,已是十分不易,任何一个地方动作慢点,都不会有现在的成果。被小扎点名我是始料未及,我感到非常荣幸。
澎湃新闻:对于外界来说,关于Facebook的人工智能实验室,一直有非常多的期待,除了darkforest项目,图像识别项目也活跃在各个报纸的版面上,除此之外,Facebook人工智能实验室的研究方向还有哪些?
田渊栋:Facebook AI Research (简称FAIR) 目前在加州门洛帕克、纽约曼哈顿和法国巴黎有三个分部,巴黎分部刚刚公开。总的来说,学术氛围是非常浓厚,大家坐在Facebook新建的20楼中央做深度学习的研究,目标是发高质量的文章,做有影响力的前沿工作。研究方向相对自由宽松,研究所需的计算资源(如GPU)相对丰富,同时也没有近期的产品压力,可以着眼长远做困难和本质的研究问题。这样的学术氛围除了MSR之外,在各大公司是极其少见的。
扎克伯格之前提过Facebook将来的三大主要方向,其中之一就是人工智能,目前看来公司也确实非常看重我们这个组。我后面就是COO,斜后方是CEO,一开始有点小慌,不过时间长了也就习惯了。
FAIR正式成立是在前年12月至去年一月,然后陆续招人,时间还不长,重要的公开工作有DeepFace,运用深度学习将人脸识别(更准确说是人脸判定)提高到人类级别。记忆网络,在深度学习中加入长期记忆(Long-term memory)以构建自然语言问答系统,开源深度学习框架Torch的更新和推广,运用快速傅利叶变换加速卷积运算的CuFFT等等。目前还有许多非常有影响力的工作正在进行中,敬请期待。
在深度学习的时代,研究和工程已经有融合的趋势,因此FAIR这两方面的大牛都有。工作气氛上来说,组内较平等,讨论自由,基本没有传统的上下级观念。若是任何人有有趣的想法,大家都会倾听并且作出评论。要是想法正确,Yann也会喜欢。
没有人逼着干活,但大家都在努力干活。
黑暗森林VS阿尔法Go谁会赢?
据田渊栋的介绍,两家公司在围棋对弈项目里使用的人工智能技术有一定的重合性,但谷歌在快速走子(Fast rollout)和估值网络(Value Network)两方面有所加强,Facebook的研究则是以开源软件Pachi的缺省策略(default policy)部分替代了快速走子的功能。
澎湃新闻:看到你从走棋网络、快速走子、估值网络、蒙特卡罗树搜索等四个方面对AlphaGo进行了分析,在这四个方面,您觉得谷歌哪个方面做得最好,与你们的差异在那里?
田渊栋:AlphaGo这个系统主要由几个部分组成:一是走棋网络(Policy Network),即给定当前局面,预测/采样下一步的走棋。二是快速走子(Fast rollout),和目标一是一样的,但在适当牺牲走棋质量的条件下,速度要比1快1000倍。三是估值网络(Value Network),给定当前局面,估计是白子胜还是黑子胜。四是蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS),把以上这三个部分连起来,形成一个完整的系统。
我们的DarkForest和AlphaGo同样是用蒙特卡罗树搜索搭建的系统。只是相较AlphaGo而言,在训练时加强了走棋网络,少了快速走子和估值网络,然后以开源软件Pachi的缺省策略(default policy)部分替代了快速走子的功能。
另外,据他们的文章所言,AlphaGo整个系统在单机上已具有了职业水平,若是谷歌愿意开几万台机器和李世石对决,相信比赛会非常精彩。
澎湃新闻:Facebook人工智能实验室主管Yann LeCun一直希望各家人工智能平台能做到开源,这样有利于人工智能的发展,你是否也赞同这种观点?为什么?
田渊栋:我十分赞同,只有充分交流才能让大家发展得更快更好。深度学习近两年的大进展很大程度上得益于像torch和caffe这样开源的计算平台,让其它人能很快复现前人结果并加以改进。
澎湃新闻:相较alphaGo取得的成绩,darkforest的下一步目标是什么?不断改进版本后,你们希望自己的围棋AI能达到什么样的水平?
田渊栋:目前还在改进中,会参加三月在日本的比赛。之后的目标暂不公开,我也在思考中。
澎湃新闻:此次alphaGo与李世石,你是看好alphaGo还是李世石?无论结果如何,我们应该如何看待这样一场对决?
田渊栋:我不做预测,我只说很期待。
澎湃新闻:谷歌和Facebook成立人工智能实验室、通过收购公司,布局人工智能,作为一名人工智能研究人员,你认为这两个公司是不是已经代表硅谷人工智能研究领域的最高水平?
田渊栋:可以说这两个实验室网罗了全球人工智能领域最顶尖的研究和工程方面的人才,并且还在继续网罗中。我们今年还会招挺多人,欢迎大家投简历。
“我对人工智能持乐观态度,但大家期望先不要太高”
科学技术的进步带来了人类生活质量的提高,同时也在改变人类。面对这些改变,有些人看到的是恐惧。他们担心当机器变得越来越智能,甚至会超过人类时,会变成可怕的恶魔。基于此,霍金、特斯拉CEO马斯克还成立了防范人工智能威胁联盟。
但田渊栋个人对人工智能持乐观态度。因为就目前的人工智能发展水平而言,还存在很多问题,在创造性工作,处理突发事件,分析未知事件等方面还远不如人类。
澎湃新闻:你曾评论说“到目前为止,人工智能系统要达到人类水平,还是需要大量样本的训练的。可以说,没有千年来众多棋手在围棋上的积累,就没有围棋AI的今天。”需要依赖于数据输入,这是不是人工智能一直未突破的瓶颈之一?如何才能找到解决方法?
田渊栋:数据是现代基于统计推断的人工智能的发动机,没有数据大家就只能回到70年代的专家系统的老路里去了。关于如何突破,所有的人工智能专家都在努力中,我现在随便说两个未经实验验证的解决方案,不免贻笑大方,这里就不展开了。方法论上说,给顶尖人才充分的自由度和大量的资源,让他们作不停的努力和尝试,容许犯错,鼓励创新,就会看到进展的。
澎湃新闻:作为研究人员,你觉得未来围棋AI能应用到人类生活的哪些领域,帮助人类改善生活?
田渊栋:太多了,说AI能改变人类生活的方方面面,是毫不夸张的。现在的成果主要是能让AI接近人的感知能力(比如说图像,语音,自然语言理解),从而增进人与AI及人与人之间的交流,降低沟通成本,对一些程序性的交流可以自动化。
澎湃新闻:有哪些人类的活动是人工智能无法替代的?
田渊栋:目前像创造性工作,处理突发事件,分析没见过的问题,这些事情,人工智能与人相比还远远不如。以后的情况我不知道,如果都能随便精准预见了,那科学家的存在就没有意义了。未来是要由我们的手去开拓的,我们的努力本身,就是“让未来变得更清楚”这一目标的一部分。
澎湃新闻:人工智能威胁论也是争议焦点,此前特斯拉CEO马斯克曾联联合霍金成立防范人工智能联盟,最近扎克伯克对此观点进行了驳斥,你怎么看待人工智能威胁论?
田渊栋:我是持乐观态度的,我的观点是:“机器会适应我们,我们也会适应机器,最后……新的人类在探索中崛起,我们有了新的三观,新的喜怒哀愁,浑然不觉旧的人类早已在欢笑中灭亡,在岁月中死去。我们所有的故事,都会被未来子孙们写进一本叫作《地球往事》的书里,每当在茶余饭后的谈及,便会招来一阵夹杂着同情与羡慕的复杂心绪,而后,他们便会抱怨难以开采的行星,抱怨不够快速的星际通信,或是追不到手的外星美女,然后,继续自己的生活。所以,继续我们的生活吧。”
作者: 原力猫 时间: 2016-4-18 15:40
很高深,慢慢看
作者: 石头脑壳 时间: 2016-4-29 10:00
提示: 作者被禁止或删除 内容自动屏蔽
作者: 唯物主义 时间: 2016-6-1 14:18
慢慢消化 看了第一楼
作者: fumino 时间: 2016-6-1 14:42
 看了这篇,感觉赶超职业指日可待
看了这篇,感觉赶超职业指日可待
作者: oysn921 时间: 2016-6-8 11:20
说句老实话,陈经这篇,扯淡的居多,嘿嘿。
作者: cateyes 时间: 2017-2-10 17:45
标题: [轉帖]陈经:AlphaGo升级成Master后的算法框架分析
http://www.guancha.cn/chenjing/2017_01_09_388464_s.shtml
陈经风云学会会员,《中国的官办经济》2017-01-09 15:51:05
【文/观察者网专栏作者 陈经】
2016年12月29日至2017年1月4日,谷歌AlphaGo的升级版本以Master为名,在弈城围棋网和野狐围棋网的快棋比赛中对人类最高水平的选手取得了60:0的压倒战绩,再次让人们对围棋AI的实力感到震惊。
之前《自然》论文对AlphaGo的算法进行了非常细致的介绍,世界各地不少研发团队根据这个论文进行了围棋AI的开发。其中进展最大的应该是腾讯开发的“刑天”(以及之前的版本“绝艺”),职业棋手和棋迷们感觉它的实力达到了2016年3月与李世石对战的AlphaGo版本。但是经过近一年的升级,Master的实力显然比之前版本要强得多,它背后的算法演变成什么样了,却几乎没有资料。本文对AlphaGo的升级后的算法框架进行深入的分析与猜测,试图从计算机算法角度揭开它的神秘面纱一角。
在1月4日AlphaGo团队的正式声明中,Deepmind提到了“our new prototype version(我们新的原型版本)”。prototype这个词在软件工程领域一般对应一个新的算法框架,并不是简单的性能升级,可能是算法原理级的改变。由于资料极少,我只能根据很少的一些信息,以及Master的实战表现对此进行分析与猜测。
下文中,我们将2015年10月战胜樊麾二段的AlphaGo版本称为V13,将2016年3月战胜李世石的版本称为V18,将升级后在网络上60:0战胜人类高手群体的版本称为V25(这个版本Deepmind内部应该有不同的称呼)。
V13与V25:从廖化到关羽
版本V13的战绩是,正式的慢棋5:0胜樊麾,棋谱公布了,非正式的快棋3:2胜樊麾,棋谱未公布。樊麾非正式快棋胜了两局,这说明版本V13的快棋实力并不是太强。
版本V18的战绩是,每方2小时3次1分钟读秒的慢棋,以4:1胜李世石。比赛中AlphaGo以非常稳定的1分钟1步的节奏下棋。比赛用的分布式机器有1202个CPU和176个GPU,据说每下一局光电费就要3000美元。
版本V25的战绩是,Master以60:0战胜30多位人类棋手,包括排名前20位的所有棋手。比赛大部分是3次30秒读秒的快棋,开始10多局人们关注不多时是20秒读秒用时更短,仅有一次60秒读秒是照顾年过六旬的聂卫平。比赛中Master每步几乎都在8秒以内落子,从未用掉过读秒(除了一次意外掉线),所以20秒或者30秒对机器是一回事。在KGS上天元开局三局虐杀ZEN的GodMoves很可能也是版本V25,这三局也是快棋,GodMoves每步都是几秒,用时只有ZEN的一半。
可以看出,版本V13的快棋实力不强。而版本V18的快棋实力应该也不如慢棋,谷歌为了确保胜利,用了分布式的版本而非48个CPU与8个GPU的单机版,还用了每步1分钟这种在AI中算多的每步用时。在比赛中,有时AlphaGo的剩余用时甚至比李世石少了。应该说这时的AlphaGo版本有堆机器提升棋力的感觉,和IBM在1997年与卡斯帕罗夫的国际象棋人机大战时的做法类似。
但是版本V25在比赛用时上进步很大,每步8秒比版本V18快了六七倍,而棋力却提升很大。柯洁与朴廷桓在30秒用时的比赛中能多次战胜与版本V18实力相当的刑天,同样的用时对Master几盘中却毫无机会。应该说版本V25在用时大大减少的同时还取得了棋力巨大的进步,这是双重的进步,一定是因为算法原理有了突破,绝对不是靠提升机器性能。而这与国际像棋AI的进步过程有些类似。
IBM在人机大战中战胜卡斯帕罗夫后解散了团队不玩了,但其它研究者继续开发国际象棋AI取得了巨大的进步。后来算法越做越厉害,最厉害的程序能让人类最高水平的棋手一个兵或者两先。水平极高的国际象棋AI不少,其中一个是鳕鱼(stockfish),由许多开发者集体开发,攻杀凌厉,受到爱好者追捧。
另一个是变色龙(Komodo),由一个国际象棋大师和一个程序员开发,理论体系严谨,攻防稳健。AI互相对局比人类多得多,二者对下100盘,变色龙以9胜89平2负领先人气高的鳕鱼。因为AI在平常的手机上都可以战胜人类最高水平的棋手,国际象棋(以及类似的中国象棋)都禁止棋手使用手机,曾经有棋手频繁上厕所看手机被抓禁赛。国际象棋AI在棋力以及计算性能上都取得了巨大的进步,运算平台从特别造的大型服务器移到了人人都有的手机上。
局面评估函数的作用
从算法上来说,高水平国际象棋AI的关键是人工植入的一些国际象棋相关的领域知识,加上传统的计算机搜索高效剪枝算法。值得注意的是,AlphaGo以及之前所有高水平AI如ZEN和CrazyStone都采用MCTS(蒙特卡洛树形搜索),而最高水平的国际象棋AI是不用的。MCTS是CrazyStone的作者法国人Remi Coulom 在2006年最先提出的,是上一次围棋人工智能算法取得巨大进步能够战胜一般业余棋手的关键技术突破。
但MCTS其实是传统搜索技术没有办法解决围棋问题时,想出来的变通办法,并不是说它比传统搜索技术更先进。实际MCTS随机模拟,并不是太严谨,它是成千上万次模拟,每次模拟都下至终局数子确定胜负统计各种选择的胜率。这是一个对人类棋手来说相当不自然的方法,可以预期人类绝对不会用这种办法去下棋。
国际象棋也可以用MCTS去做,但没有必要。谷歌团队有人用深度学习和MCTS做了国际象棋程序,但是棋力仅仅是国际大师,并没有特别厉害。高水平国际象棋算法的核心技术,是极为精细的“局面评估函数”。而这早在几十年前,就是人工智能博弈算法的核心问题。国际象棋的局面评估函数很好理解,基本想法是对皇后、车、马、象、兵根据战斗力大小给出不同的分值,对王给出一个超级大的分值死了就是最差的局面。一个局面就是棋子的分值和。
但这只是最原始的想法,子力的搭配、兵阵的形状、棋子的位置更为关键,象棋中的弃子攻杀极为常见。这需要国际象棋专业人士进行极为专业细致的估值调整。国际象棋AI的水平高低基本由它的局面评估函数决定。有了好用的局面评估函数以后,再以此为基础,展开一个你一步我一步的指数扩展的博弈搜索树。在这个搜索树上,利用每个局面计算出来的分值,进行一些专业的高效率“剪枝”(如Alpha-Beta剪枝算法)操作,缩小树的规模,用有限的计算资源尽可能地搜索更多的棋步,又不发生漏算。
图为搜索树示例,方块和圆圈是两个对手,每一条线代表下出一招。局面评估后,棋手要遵守MIN-MAX的原则,要“诚实”地认为对手能下出最强应对再去想自己的招。有局面评估分数的叶子节点其实不用都搜索到,因为理论上有剪枝算法证明不用搜索了。如一下被人吃掉一个大子,又得不到补偿的分枝就不用继续往下推了。这些搜索技术发展到很复杂了,但都属于传统的搜索技术,是人可以信服的逻辑。
国际象棋与中国象棋AI发展到水平很高后,棋手们真的感觉到了电脑的深不可测,就是有时电脑会下出人类难于理解的“AI棋”。人类对手互相下,出了招以后,人就会想对手这是想干什么,水平相当的对手仔细思考后总是能发现对手的战术意图,如设个套双吃对手的马和车,如果对手防着了,就能吃个兵。而“AI棋”的特征是,它背后并不是一条或者少数几条战术意图,而是有一个庞大的搜索树支持,人类对手作出任何应对,它都能在几手、十几手后占得优势,整个战略并不能用几句话解释清楚,可能需要写一篇几千字的文章。
这种“AI棋”要思考非常周密深远,人类选手很难下出来。近年来中国象棋成绩最好的是王天一,他的棋艺特点就是主动用软件进行训练,和上一辈高手方法不同。王天一下出来的招有时就象AI,以致于有些高手风言风语影射他用软件作弊引发风波,我认为应该是训练方法不同导致的。国际象棋界对软件的重视与应用比中国象棋界要强得多,重大比赛时,一堆人用软件分析双方的着手好坏,直接作为判据,增加了比赛的可看性。
软件能下出“AI棋”,是因为经过硬件以及算法的持续提升,程序的搜索能力终于突破了人类的脑力限制,经过高效剪枝后,几千万次搜索可以连续推理多步并覆盖各个分枝,在深度与广度方面都超过人类,可以说搜索能力已经超过人类。
其实最初的围棋AI也是用这个思路开发的,也是建立搜索树,在叶子节点上搞局面评估函数计算。但是围棋的评估函数特别难搞,初级的程序一般用黑白子对周边空点的“控制力”之类的原始逻辑进行估值,差错特别大,估值极为离谱,棋力极低。无论怎么人工加调整,也搞不好,各种棋形实在是太复杂。很长时间围棋AI没有实质进步,受限于评估函数极差的能力,搜索能力极差。
实在是没有办法了,才搞出MCTS这种非自然的随机下至终局统计胜率的办法。MCTS部分解决了估值精确性问题,因为下到终局数子是准确的,只要模拟的次数足够多,有理论证明可以逼近最优解。用这种变通的办法绕开了局面评估这个博弈搜索的核心问题。以此为基础,以ZEN为代表的几个程序,在根据棋形走子选点上下了苦功,终于取得了棋力突破,能够战胜一般业余棋手。
接下来自然的发展就是用深度学习对人类高手的选点直觉建模,就是“策略网络”。这次突破引入了机器学习技术,不需要开发者辛苦写代码了,高水平围棋AI的开发变容易了。即使这样,由于评估函数没有取得突破,仍然需要MCTS来进行胜率统计,棋力仍然受限,只相当于业余高手。
“价值网络”横空出世
AlphaGo在局面评估函数上作出了尝试性的创新,用深度学习技术开发出了“价值网络”。它的特点是,局面评分也是胜率,而不是领先多少目这种较为自然的优势计算。但是从《自然》论文以及版本V13与V18的表现来看,这时的价值网络并不是太准确,不能单独使用,应该是一个经常出错的函数。论文中提到,叶子节点胜率评估是把价值网络和MCTS下至终局混合使用,各占0.5权重。这个意思是说,AlphaGo会象国际象棋搜索算法一样,展开一个叶子节点很多的树。
在叶子节点上,用价值网络算出一个胜率,再从叶子节点开始黑白双方一直轮流走子终局得出胜负。两者都要参考,0.5是一个经验性的数据,这样棋力最高。这其实是一个权宜之计,价值网络会出错,模拟走子终局也并不可靠,通过混合想互相弥补一下,但并不能解决太多问题。最终棋力还是需要靠MCTS海量模拟试错,模拟到新的关键分枝提升棋力。所以版本V18特别需要海量计算,每步需要的时间相对长,需要的CPU与GPU个数也不少,谷歌甚至开发了特别的TPU进行深度神经网络并行计算提高计算速度。
整个《自然》论文给人的感觉是,AlphaGo在围棋AI的工程实施的各个环节都精益求精做到最好,最后的棋力并不能简单地归因于一两个技术突破。算法研发与软件工程硬件开发多个环节都不计成本地投入,需要一个人数不小的精英团队全力支持,也需要大公司的财力与硬件支持。V13与V18更多给人的感觉是工程成就,之前的围棋AI开发者基本是两三个人的小团队小成本开发,提出了各式各样的算法思想,AlphaGo来了个集大成,终于取得了棋力突破。
即使这样,V18在实战中也表现出了明显缺陷,输给李世石一局,也出了一些局部计算错误。如果与国际象棋AI的表现对比,对人并不能说有优势,而是各有所长。人类高手熟悉这类围棋AI的特点后,胜率会上升,正如对腾讯AI刑天与绝艺的表现。
ZEN、刑天、AlphaGo版本V18共同的特点是大局观很好。连ZEN的大局观都超过一些不太注意大局的职业棋手,但是战斗力不足。这是MCTS海量模拟至终局精确数目带来的优势,对于地块的价值估计比人要准。它们共同的弱点也是局部战斗中会出问题,死活搞不清,棋力高的问题少点。这虽然出乎职业棋手的预料,从算法角度看是自然的。海量终局模拟能体现虚虚的大局观,但是这类围棋AI的“搜索能力”仍然是不足的,局面评估函数水平不高,搜索能力就不足,或者看似搜得深但有漏洞。正是因为搜索能力不足,才需要用MCTS来主打。
但是AlphaGo的价值网络是一个非常重要而且有巨大潜力的技术。它的革命性在于,用机器学习的办法去解决局面评估函数问题,避免了开发者自己去写难度极大甚至是不可能写出来的高水平围棋局面评估函数。国际象棋开发者可以把评估思想写进代码里,围棋是不可能的,过去的经验已经证明了这一点。机器学习的优点是,把人类说不清楚的复杂逻辑放在多达几百M的多层神经网络系数里,通过海量的大数据把这些系数训练出来。
给定一个围棋局面,谁占优是有确定答案的,高手也能讲出一些道理,有内在的逻辑。这是一个标准的人工智能监督学习问题,它的难度在于,由于深度神经网络结构复杂系数极多,需要的训练样本数量极大,而高水平围棋对局的数据更加难于获取。Deepmind是通过机器自我对局,积累了2000万局高质量对局作为训练样本,这个投入是海量的,如果机器数量不多可能要几百年时间,短期生成这么多棋局动用的服务器多达十几万台。但如果真的有了这个条件,那么研究就是开放的,怎么准备海量样本,如何构建价值网络的多层神经网络,如何训练提升评估质量,可以去想办法。
AlphaGo团队算法负责人David Silver在2016年中的一次学术报告会上说,团队又取得了巨大进步,新版本可以让V18四个子了,主要是价值网络取得了巨大进步。这是非常重要的信息。
V25能让V18四个子,如果V18相当于人类最高水平的棋手,这是不可想象的。根据Master对人类60局棋来看,让四子是绝对不可能的,让二子人类高手们都有信心。我猜测,V18是和V25下快棋才四个子还输的。AlphaGo的训练与评估流水线中,机器自我对局是下快棋,每步5秒这样。2016年9月还公布了三局自我对局棋谱,就是这样下出来的。V18的快棋能力差,V25在价值网络取得巨大进步能力后,搜索能力上升极大,只要几秒的时间,搜索质量就足够了。为什么价值网络的巨大进步带来的好处这么大?
如果有了一个比V18要靠谱得多的价值网络,就等于初步解决了局面评估函数问题。这样,AlphaGo新的prototype就更接近于传统的以局面评估为核心的搜索框架,带有确定性质的搜索就成为算法能力的主要力量,碰运气的MCTS不用主打了。因此,V25对人类高手的实战表现,可以与高水平国际象棋AI相当了。
我可以肯定V25的搜索框架会给价值网络一个很高的权重(如0.9),只给走子至终局数子很低的权重。如果局面平稳双方展开圈地运动,那么各局面的价值网络分值差不多,MCTS模拟至终局的大局观会起作用。如果发生局部战斗,那么价值网络就会起到主导作用,对战斗分枝的多个选择,价值网络都迅速给出明快的判断,通过较为完整的搜索展开,象国际象棋AI一样论证出人类棋手看不懂的“AI棋”。
上图为Master执白对陈耀烨。在黑子力占优的左上方,白20挂入,黑21尖顶夺白根据地意图整体攻击,白22飞灵活转身是常型,23团准备切断白,这时Master忽然在24位靠黑一子。Master比起之前的版本V18,感觉行棋要积极一些,对人类棋手的考验也更多。可以想见这里黑内扳外扳两边长脱先各种应法很多,并不是很容易判断。
但是如果有价值网络对各个结果进行准确估值,Master可能在下24的时候就已经给出了结论,黑无论如何应,白棋都局势不错。陈耀烨自战解说认为,24这招他已经应不好了,实战只好委屈地先稳住阵脚,复盘也没有给出好的应对。同样的招法Master对朴廷桓也下过。
上图为Master执白对芈昱廷,左上角的大雪崩外拐定式,白下出新手。白44职业棋手都是走在E13长的,后续变化很复杂。但是Master却先44打一下,下了让所有人都感到震惊的46扳,在这个古老的定式下出了从未见过的新手。这个新手让芈昱廷短时间内应错了,吃了大亏。后来芈昱廷自战回顾时说应该可以比实战下得好些,黑棋能够厚实很多,但也难说占优。但是对白46这招还没有完全接受。这个局面很复杂,有多个要点,Master的搜索中是完全没有定式的概念的。
我猜测它会各种手段都试下,由于价值网络比过去精确了,可以建立一个比较庞大的搜索树,然后象国际象棋AI一样多个局面都考虑过之后综合出这个新手。这次Master表现得不怕复杂变化,而之前版本感觉上是进行大局掌控,复杂变化算不清绕开去。Master却经常主动挑起复杂变化,明显感觉搜索能力有进步,算路要深了。
局面评估函数精确到一定程度突破了临界点,就可以带来搜索能力的巨大进步。因为开发者可以放心地利用局面评估函数进行高效率的剪枝,节省出来的计算能力可以用于更深的推导,表现出来就是算得深算得广。实际人类的剪枝能力是非常强大的,计算速度太慢,如果还要去思考一些明显不行的分枝,根本没办法进行细致的推理。在一个局面人类的推理,其实就是一堆变化图,众多高手可能就取得一致意见了。而Master以及国际象棋AI也是走这个路线了,它们能摆多得多的变化图,足以覆盖人类考虑到的那些变化图给出靠谱的结论。
但这个路线的必须依靠足够精确的价值网络,否则会受到多种干扰。一是估值错了,好局面扔掉坏局面留着选错棋招。二是剪枝不敢做,搜索大量无意义的局面,有意义的局面没时间做或者深度不足。三是要在叶子节点引入快速走子下完的“验证”,这种验证未必靠谱,价值网络正确的估值反而给带歪了。
从实战表现反推,Master的价值网络质量肯定已经突破了临界点,带来了极大的好处,思考时间大幅减少,搜索深度广度增加,战斗力上升。AlphaGo团队新的prototype,架构上可能更简单了,需要的CPU数目也减少了,更接近国际象棋的搜索框架,而不是以MCTS为基础的复杂框架。比起国际象棋AI复杂的人工精心编写的局面评估函数,AlphaGo的价值网络完全由机器学习生成,编码任务更为简单。
理论上来说,如果价值网络的估值足够精确,可以将叶子节点价值网络的权重上升为1.0,就等于在搜索框架中完全去除了MCTS模块,和传统搜索算法完全一样了。这时的围棋AI将从理论上完全战胜人,因为人能做的机器都能做,而且还做得更好更快。而围棋AI的发展过程可以简略为两个阶段。第一阶段局面估值函数能力极弱,被逼引入MCTS以及它的天生弱点。第二阶段价值网络取得突破,再次将MCTS从搜索框架逐渐去除返朴归真,回归传统搜索算法。
由于价值网络是一个机器学习出来的黑箱子,人类很难理解里面是什么,它的能力会到什么程度不好说。这样训练肯定会碰到瓶颈,再也没法提升了,但版本V18那时显然没到瓶颈,之后继续取得了巨大进步。通常机器学习是模仿人的能力,如人脸识别、语音识别的能力超过人。但是围棋局面评估可以说是对人与机器来说都非常困难的任务。
职业棋手们的常识是,直线计算或者计算更周密是可以努力解决的有客观标准的问题,但是局面判断是最难的,说不太清楚,棋手们的意见并不统一。由于人的局面评估能力并不太高,Master的价值网络在几千万对局巧妙训练后超过人类是可以想象的,也带来了棋力与用时表现的巨大进步。但是可以合理推测,AlphaGo团队也不太可能训练无缺陷的价值网络,不太可能训练出国际象棋AI那种几乎完美的局面评估函数。
我的猜测是,Master现在是一个“自信”的棋手,并不象之前版本那样对搜索没信心靠海量模拟至终局验算。它充分相信自己的价值网络,以此为基础短时间内展开庞大的搜索树,下出信心十足算路深远的“AI棋”,对人类棋手主动挑起战斗。这个姿态它是有了。但是它这个“自信”并不是真理,它只是坚定地这样判断了。肯定有一些局面它的评估有误差,如围棋之神说是白胜的,Master认为是黑胜。人类棋手需要找到它的推理背后的错误,与之进行判断的较量,不能被它吓倒。
上图是Master执黑对孟泰龄。本局下得较早,Master虽然连胜但没有战胜太多强手,孟泰龄之前有战胜绝艺的经验,心理较为稳定并不怕它,本局发挥不错。Master黑69点入,71、73、75将白棋分为两段发起凶猛的攻击。但是孟泰龄下出78位靠的好手,局部结果如下图。
黑棋右边中间分断白棋的四子已经被吃,白棋厚势与左下势力形成呼应,右上还有R17断吃角部一子的大官子。黑棋只吃掉了白棋上边两子,这两子本就处于受攻状态白并不想要。这个结果无论如何应该是白棋获利,Master发生了误算,或者局面评估失误。
现在职业棋手与AlphaGo团队的棋艺竞争态势可能是这样的。AlphaGo不再靠MCTS主导搜索改而以价值网络主打,思考时间大大缩短,在10秒以内就达到了极高棋力,之后时间再长棋力增长也并不多。棋力主要是由价值网络的质量决定的,堆积服务器增加搜索时间对搜索深度广度意义并不太大。所以Master已经较充分的展示了实力,并不是说还有棋力强大很多的版本。这和国际象棋AI类似,两个高水平AI短时间就能大战100局,并不需要人类那么长的思考时间。
Master的60局快棋击中了人类棋艺的弱点,它极为自信地主动发起挑战敢于导入复杂局面,而人类高手却没有能力在30秒内完善应对这些不太熟悉的新手。而这些新手并不是简单的新型,背后有Master的价值网络支持的庞大搜索树。如果价值网络的这些估值是准确的,人类高手即使完美应对,也只能是不吃亏,犯错就会被占便宜。有些局面下,价值网络的估计会有误差,这时人类高手有惩罚Master的机会,但需要充足的时间思考,也要有足够的自信与Master的判断进行较量。这次60局中棋手由于用时太短心态失衡很少做到,一般还是会吃亏。
以下是我对柯洁与AlphaGo的人机大战的建议:
1. 要对机器有足够了解,不要盲目猜测。可以简单的理解,它接近一个以价值网络为基础的传统搜索程序。
2. 要相信机器并不完美。如果它的局面评估函数没有错误了,或者远远超过人,那就和国际象棋AI一样不可战胜了。但围棋足够复杂,即使是几千万局的深度学习,也不可能训练出特别好的价值网络,一定会有漏洞与误差。只是因为人的局面评估也不是太好,才显得机器很厉害。
3. 这次机器会坚定而自信地出手,它改变了风格,在局面仍然胶着的时候不会回避复杂变化。因为它的搜索深度广度增加了,它认为自己算清了,坚定出手维护自己的判断,甚至会主动扑劫造劫。
4. 机器的退让是在胜定的情况下,它认为反正是100%获胜了,就随机选了一手。后半盘出现这种情况不用太费劲去思考了,应该保留体力迅速下完,下一局再战斗。
5. 机器的大局观仍然会很好,基于多次模拟数空,对于虚空的估计从原理上就比人强,这方面人要顶住但不能指望靠此获胜。还是应该在复杂局部中与机器进行战斗,利用机器价值网络的估值失误,以人对局面估计的自信与机器的自信进行比拼。机器是自信的,人类也必须自信。也许机器评估正确的概率更大,但是既然都不完美,人类也可能在一些局面判断更为正确。
6. 机器对稍复杂战斗局面的评估是有庞大搜索树支持的,并不会发生简单的漏算,不应该指望找到简单的手段给机器毁灭性打击。由于人类的思考速度慢,时间有限,不能进行太全面的思考。应该集中思考自己判断不错的局面,围绕它进行论证。如果这个判断正好是人类正确、机器错误,那人是有机会占优的。
通过以上分析,我对人机大战柯洁胜出一局甚至更多局还是抱有一定期望的。希望柯洁能够总结分析围棋AI的技术特点,增加自信,针锋相对采取正确的战略,捍卫人类的围棋价值观。
本文系观察者网独家稿件,文章内容纯属作者个人观点,不代表平台观点,未经授权,不得转载,否则将追究法律责任。关注观察者网微信guanchacn,每日阅读趣味文章。
作者: hidear 时间: 2017-2-11 00:25
Xie Xie.
作者: lione3000 时间: 2017-2-17 01:56
用黎曼猜想可击败一切Go
作者: 保德弈庄 时间: 2017-3-14 21:35
Go借围棋证明自己,是科技,我们人与人的对弈是一种艺术创作,科技与艺术有相通的一面也有本质的区别,科技与艺术有互为印证的一面,也各有各的趣向。
作者: go1 时间: 2017-3-15 14:05
看看~
作者: cateyes 时间: 2017-4-1 14:58
专访田渊栋:AlphaGo之后研究智能围棋还有什么意义
http://k.sina.cn/article_2118746 ... doct=0&rfunc=23
 03月27日 21:59
03月27日 21:59
没有什么是永垂不朽的,没有什么会一直昌盛,所以我宁愿做点真正有意义的事情,来致敬这个风起云涌的人工智能时代。
-------题记。
近日,田渊栋受地平线曾经在Facebook的同事邀请,赴中国做了一期大牛讲堂,分享了关于游戏和增强学习等的话题。分享会后,AI科技评论采访了田渊栋,就他为什么离开Google无人驾驶团队去Facebook人工智能研究院,现在正在做的工作,如何平衡工作中理论和应用的比率,怎么看待绝艺和AlphaGo的棋艺水平,怎么看待智能围棋的实用价值,接受了AI科技评论的采访。以下是采访正文。
1. AlphaGo目前是世界第一的围棋选手,在此之后,研究智能围棋还有什么意义?
我觉得围棋是很有意思的游戏,AlphaGo虽然把它做出来了。但很多东西的做法和人是不一样的。人在学围棋的时候有很多概念,按照概念做判断,但是机器解决他还是比较暴力的。
一方面,你可以说人用概念来做推理局限了他的计算能力,体现出人本身有一个高度抽象的能力,就是用非常非常局限的计算能力,能达到那么强的棋力。而AlphaGo就是用非常多的计算能力去弥补这些不足,所以恰恰是互补的,我相信还是有意义的。
另一方面,联系到后面那个问题(目前你的研究团队,对围棋AI的研究进展到何种地步?相比AlphaGo如何。),我们这边在开源之后就先放在那儿了,可能等到以后我们有新想法再拿过来试一试。我们这边是七八十人的研究机构,要让我们花二十人做围棋,这个是不可能的。我们这边都是很有名的研究员,这些研究员每个人都有自己的方向,像计算机视觉和自然语言处理等等,不可能把自己的方向放弃掉来专门(搞围棋)。
最后,从本质上来说,我们的风格跟其它公司不一样。我们研究员的一个目标是说在大家不做这个东西的时候,在比较冷门或者大家不相信它能做得更好的时候去做它,证明这条路能走通。比如说我们在做DarkForest的时候,围棋还是很冷门的方向,大家都不认为围棋可以做出来。我们的文章比AlphaGo早了三个月出来,证明这个东西确实有效果,而且能提高挺多的,这就是我们的贡献。我之前在采访里面说过,好的研究就是“于无声处听惊雷”。
像星际这样的游戏,大家都不知道怎么做,研究员们的任务就是要想办法找到一些突破口,这个突破口可能没有人想到,或者是没有人觉得能做成,我们的目标是在这儿。我回到第一个问题,就是说智能围棋之后还有什么意义,就是我刚才说的,如果有人愿意想要做下去的话, 就看能不能自动从里面学出一些概念来,学出一些有意思的东西,比如说人有大局观或者是大势,或者是各种下棋时候的概念,概念是不是能从这里面自动学出来。像这些,目前大家都没什么办法。
(你说大局观吗?)
对,像这样的东西其实对于我们如何理解人的思维方式是更重要的。职业棋手是很厉害的,人脑的神经传导是毫秒级的,这点时间机器可以干很多事情,但人就是用这么慢的处理速度达到了这么强的水平。2. 绝艺和AlphaGo有差距么,差距是多少,是什么造成了这种差距?
这个我稍微看了一下,我觉得绝艺肯定是比Zen要强挺多,200手不到就让Zen认输了。我之前看新闻是它对职业棋手可以战胜80%甚至更高,所以我相信它已经是做得非常好了,我相信它肯定是超过了或者是相当于AlphaGo之前Paper(AI科技评论注:2016 年 1 月 28 日,Deepmind 公司在 Nature 杂志发表论文 Mastering the game of Go with deep neural networks and tree search,介绍了 AlphaGo 程序的细节。)的水平,但是它跟现在的Master相比,可能还是有差距。3. 跟AlphaGo 3月份比赛的水平比如何?
跟3月份(对战李世石)的时候这个我不好说,我只能说和Nature那篇论文相比做得好, 当然了跟Master比是有差距的,现在Master所有对战是全部都是赢的,没有输的,胜率是100%,而且都是赢的莫名其妙。Master赢了你,你都不知道什么地方出错了,好像下得挺好的,然后就输掉了。所以就是已经到了不知道错哪儿的程度了。我相信他们应该用别的方法做训练的,而不是单纯拓展之前的文章。像我是听说他们最近把训练好的值网络单独拿出来,根据它再从头训练一个策略网络。我觉得这样做的好处是会发现一些看起来很怪但其实是好棋的招法,毕竟人类千百年下棋的师承形成了思维定式,有些棋在任何时候都不会走,所以按照人类棋谱训练出来的策略网络终究会有局限性;而用值网络作为指导,从头训练一个策略网络的话,确实会发现很多新招。
(AlphaGo用其他的方法迭代的?)
我相信他们也用了别的办法,但是细节我也不知道,因为我最近也没有做,所以我也不知道他们用什么样的办法,我觉得这方面需要创新。4. 绝艺这次是跟电脑围棋比赛,跟下一次的真人比赛区别在哪?
电脑围棋我们之前也参加过,就是大家坐着,连上之后让计算机自己下,下到什么地方就说我输了你输了,然后就结束了,有可能说我们看看剩下好像不行了,但是机器误判,就让人去认输。 基本上是这样的过程。
(那我可以这样理解吗?跟电脑围棋比赛的是两个既定程序的对战,比如说电脑围棋绝艺跟真人,比如柯洁对战的时候,是变动性更大一点,是吗?)
我相信是的,因为电脑围棋至少在之前都是有些明显的风格,比如说有些喜欢在角上和你拼,不愿意去外面抢大场。人可能能看出来这个风格,就会击败它,特别是水平不是很高的两个AI下的话,很明显能看出问题,比如我们DarkForest就有死活的问题,我们自己会说,你看这里下得不对,肯定是这里下错了,这个地方他可能判断有问题,以为这块棋是活的,其实是死的,所以会有各种各样的问题。当然了,如果是达到绝艺或者是AlphaGo这样的水平的话,我肯定是看不出来,我需要计算机辅助帮我下到后面才能看到,但是我相信职业棋手还是能看出来,但Master我不知道,我不是特别清楚。5. 以DarkForest为例,除了围棋,这种完全信息博弈的游戏智慧要应用在其他领域需要解决哪些问题?
我觉得现在这个系统是针对于某个问题做特别优化,我之前在 talk里也说了,那么多方法,要依照不同的游戏用不同的方法,没有那么通用的。比如说你在国际象棋上用蒙特卡洛树搜索肯定是不行的,你可能漏搜了某一条特别重要的分支,然后导致一个杀王的走棋序列没有看到,这是非常有可能的。所以整个AlphaGo是一个大的系统工程和框架结构,它需要有几个人每天花时间在上面,还得每天不停地调啊调。所以说,现在所谓的 “人工智能” 还是比较弱的,还是需要人去监督,然后把它做出来。
(如果是要针对某一个特定领域呢?)
就是我刚才说的,你先要对这个领域有了解,然后去设计。比如说围棋和国际象棋就不一样,国际象棋每步的可能性比较少,对局面的判断相对容易,因为这个原因,你要换一个方法做,而不是用原来的方法做。所以对于方法的选择,其实是完全依赖于这个问题本身的,所以这个是需要大量的人工智能相关知识才能做出来的。6. 你刚才讲PPT的时候,讲到你们的围棋理论可以应用在游戏方面,还有其它现实生活中的应用场景吗?
一个问题就是说像完全信息博弈游戏,你知道你下完这步后局面会变成什么样子,你心里非常非常清楚。但到了现实世界的时候,有时候并不那么清楚,没有一个现实世界给你玩,你做完决定之后你得对这个决定的后果负责,所以对这个世界在你下完决定之后变成什么样子,你要有一个大概的估计。
所以你在现实世界做规划的时候,其实需要一个前向模型(forward model), 就是你对将来会发生什么事情的一个预计,前向模型是一种规划,是对将来会发生什么样事情的预计 。比如说你下完这步之后,可能整个情况变成什么样子,之后你再做下一步的计划。所以这个其实是很大的问题,是游戏和现实生活中是不同的。7. 能详细介绍一下前向模型?
前向模型就是你要对现实世界的运行规律做一个模型。比如说你这个房子过了几年会变成什么样子,比如说这朵花过几年会变成什么样子。你当然不可能能预测所有细节,要找到关键性的方面,才能让你的蒙特卡罗树之类的搜索产生效果。比如一个国家30年后会怎么样,和现在这束花是不是会枯萎没什么关系,但可能和大家的收入统计有关系。所以关键就是怎么对现实世界来做出抽象的建模。8. 我们看到绝艺那边,腾讯的副总裁姚星说他们可以把其 “精准决策” 能力用在无人驾驶,量化金融,辅助医疗等,这个是不是说得太早了?
长远来说,通过在绝艺上投入的人力和物力,这些工程师的思考本身可以变成经验。比如说它在人工智能上通过对于绝艺的提高,他知道了蒙特卡罗树的适用范围,知道了增强学习算法的适用范围,对这些算法有一个切身的理解。这样之后,如果去从事其它方向的AI,就更加得心应手 。
我不知道“绝艺”是怎么做的,如果他们用的是Alphago相似的(原理)的话,要用到其他领域上,就不是特别容易 。比如说像辅助医疗,可能更多的是去识别图片,去怎么样去找到病变组织,这个其实更多的是图像识别的问题,而不是说关于决策的问题。所以这个其实关系不是特别大,但是不好说,说不定他们有方法。9. 李开复之前说 “AlphaGo 其实做了相当多的围棋领域的优化,除了系统调整整合之外,里面甚至还有人工设定和调节的一些参数,因此还不能算是一个通用技术平台,不是一个工程师经过调动API就可以使用的,而且还距离比较远。”假如要应用在其他领域,以金融为例,这套系统大概需要改动或调整多少?
这个我也不知道多少,感觉是完全不一样的。你说金融领域,关键是你想要解决什么问题,你想预测股票价格,还是想要预测什么?
(比如信用体系一般比较多。)
根据不同的具体问题可能又是完全不一样的方法,所以你没有办法说把这套框架用在某一个很大的领域,因为这个领域有很多问题,你得列出来,对应每个问题去想这个方法能不能用,所以我觉得这个问题其实很难回答。
(这个是要靠AI加某个垂直应用场景的实践,是吧?)
嗯是的。目前为止现在还不存在一个强人工智能,像人一样什么都可以学会,现在没有这样的东西,所以现在对应具体的问题我要具体分析,根据这个问题再分析,决定用什么样的模型去做它比较好,所以现在是处于这样的状态。所以说机器还不能自己决定用什么模型,还是需要人的输入 。10. 你除了围棋还有其他的研究领域吗?
我们现在主要在做增强学习在游戏上的应用。比如说我在Talk里面讲了围棋和最近在第一人称射击游戏上的应用。另外我也做理论,比如说对于二层神经网络做一些收敛性分析,像这个非凸优化问题,要怎么分析才是好的。
(现在最主要的哪一部分是重点?是理论还是偏应用。)
重点当然是偏应用。理论这个是我以前读博的方向,也是我个人爱好,我自己比较喜欢,觉得深度学习之所以效果好,肯定有其背后的原因,这个是很重要的问题,需要人去理解,不能放弃。当然纯做理论风险比较大,这个大家都知道。11. 其实之前看你知乎的文章,好像是讲过目前深度学习在复杂推理的一些,还有今天的分享里面你也讲了有一些进展和挑战,在这么多挑战里面,最大的一个挑战是什么?
其实有很多点是挺关键的,没有特别重要的,说我们就差这个点了,不是这样的 。其中一个就是你怎么样去像人那样有高层的建模能力,人可能对一件事情会有比较整体的把握。什么是战略上的。什么是战术上的,什么是具体执行上的。人在处理问题时很自然就会有这样层次式的思考方式。目前为止很多人想做这个。虽然你可以设计很多模型,但没有看到特别稳定的,很多模型听起来很好,但是训练的时候,效果会有问题,会有很多实际的问题,没办法做到跟你想象中的那么好,这是一个问题。另外比如说,如何让机器能在外界监督信号极度稀缺的情况下学习,如何做无监督学习,如何把传统符号推理和深度学习结合起来。12. 你刚才说的目前研究的领域来说,能透露一下你最近一段时间比较重要的进展?
我觉得,理论上来说有一些小小的进展,我之前做了一篇文章研究了两层神经网络的动力学系统,神经网络它是怎么收敛的,需要什么条件。 像这个就是更偏研究类型的。实践上来说,有一些东西我们在做,不方便说。另外就是多看文章,现在还处在一个积累的过程,多看点儿文章,多理解一些别人做的工作,就会有一些更多的想法。
下一步工作也是围绕上面说的那些,继续往下进行?
对。13. 你目前负责项目和研究领域在整个Facebook公司的架构里面,是处于一个什么样的位置,起什么样的作用?
其实现在是这样的,我们组是比较偏研究的,所以我们组的东西不一定要跟产品组有直接联系。我们做的东西都会比较前沿一点,不一定会有直接的应用,这是我们这个组很好的地方。我们公司也赋予这样的自由度。你想,你做的东西完全跟产品挂钩,每隔几个月就要求汇报进展,那这样的话最后的结果就是大家只找最容易做的那些方向,在原来的系统上修修补补。这样大家就不会愿意去想更多的东西了。
(像您刚才说的做研究,需要把一个现在还冷门的东西钻进去。)
对,比如说训练围棋,当时没有多少人知道这个东西。做研究最重要的是能够在那么多方向上,你能看到一个方向是对的,愿意花时间把它做出来,证明它是对的,这个是很重要的。
(之前看过您那篇在谷歌和Facebook的一个比较,在谷歌是没有这种自由度的?)
不能这么说。因为在谷歌时我在无人车组,这是个产品组,决定了必须要有一个非常清楚的脉络和将来的走向。我当时其实也是想做一些开放性的东西,但是觉得环境也不是特别适合,所以就走了,这是原因之一,我并不是说这个组不好,这个组挺好的,确实是因为我个人的志向和组里的发展方向不一致,所以我就走了。14. 你其实特别喜欢写博客和杂文,甚至我还看到有古文,我想问写作不管是中文的还是英文的,对于你研究来说有什么帮助?
这个我觉得是一个思考的方式,东西要写下来之后你才知道什么地方出问题了,一个典型的例子就是做数学证明嘛,你觉得好像是对的,但是你写下来才能证明,很有可能一落笔就发现错误了,这个是司空见惯的事情。
(但是其实写博客和写论文还是两种东西嘛,因为写博客可能不会写得那么深。)
论文当然抠得细得多,但大方向都是一样的 。写博客的时候一样要有逻辑,很多话当时想的是这样,但是写下来发现这两句话不连贯,或者是逻辑不通,所以你在整理的过程中其实就是在整理你的思路,这个是挺重要的。15. 经常看见你说表达的重要性,它在你不管是做研究还是之前在谷歌做产品的时候,它扮演了一个什么样的角色?
这个对研究来说非常重要,研究者的一部分工作是要把自己的成果公诸于世。要以清楚的语言概括在做什么,所以这个其实是我作为这个职位的要求之一,所以这个重要性就不用多谈了。
(必须要把现在这个事情给别人说清楚,得到别人的认可?)
对,你要跟别人说清楚,当然公司里面还好,但你在学校里边的时候,你在团队里面作为技术带头人,必须出去跟其他公司谈,或者说跟上层说我需要资源做这样的事情。这样表达能力就非常重要了,如果你没有办法表达清楚你想要做什么的话,别人不一定能相信你,也不会给你各种资源。另外比如说你遇到的人才,觉得你做的东西他没听懂,或者是不知道你在做什么,他也不会愿意跟你一起共事。作为一个研究员来说,或者是任何在研究这条路上愿意走的后辈人来说,这个很重要。16. 对于AI领域的后进者们,比如说学生、创业者或者是研究者们来说,你作为一个过来人,当然还在继续往前走,对他们有什么建议?
第一点,我不是什么过来人,我还要往前走,我也觉得我也只是很多方向刚开始的人,我也不觉得我是一个非常资深的研究员。你之前说我是高级研究员,我们组没有高级研究员这个头衔。
(你现在在Facebook的头衔是什么?)
头衔就是研究科学家,其实就是研究员。我也不觉得我自己做得有多好,只能说很多事情尽力了 。如果你要翻一下我两三年前的文章,我之前是做非凸优化在图像扭曲上的理论分析的,很荣幸地拿了马尔奖提名。我都不是做这方面(深度学习)的,我也不是做强化学习的,这些方向都是我最近觉得很有意思,然后自己学并且尝试做的。所以从这方面来说,我对目前我的工作觉得还行,想想只有一两年时间,会有这样的知名度和曝光率,这已经是出乎我的意料了。但是不管怎么样,曝光率再高,我觉得我自己还是要往前走的,我有很多东西不懂的,前面的路还很长的。所以要说对于其他人的建议,我觉得是就静下心来做事情,文章该看的要看,该学的要学,程序该写的要写,该调通的调通,一步一步往前走。
(就是把眼前的事情做好?)
对。当然方向还要看清楚的。做为一个研究者,要自己看文章定方向,不能人云亦云,这个是身为科研人员最重要的特质。然后做自己想做的事情,重要的就是要做自己想做的事,并且花时间在上面。不要说今天公司有很多钱,我就去了,这样的话对将来的发展不是特别好的,希望大家能找到自己想做的方向,主要是这一点。还有就是珍惜时间吧,大家的时间都是很宝贵的,如果愿意做一些事情,就早点行动,把事情很快地做好。另外要不断地提高自己。小结:
AI科技评论在采访田渊栋的时候,
在问到DarkForest现在的进展时,他表示 “我们这边其实目前还没有继续做,在开源之后就先放在那儿了。”。
在说道人工智能有什么意义的时候,他表示“就是我刚才说的,如果你继续做下去的话,我们想能不能自动从这里面学出一些概念来,学出一些有意思的东西……像这样的东西其实对于我们如何理解人的思维方式是更重要的。”
在问道你现在在Facebook的头衔是什么时,他表示我的“头衔就是研究科学家,其实就是研究员。”
类似这样的风格的回答很多很多,给近在迟尺的AI科技评论展现了一个直白坦率,严格待己,谦虚待学的生动形象。这跟我们采访AI业界公司大佬时他们觉得他们能解决这个问题,他们没遇到什么困难,他们即将所向披靡的那一面然不同,眼前的这个年轻科学家体现的是学界人士低调,谨慎,求是的另一面。但值得一提的事,AI科技评论看到那张谦逊却带了一点点桀骜不驯的脸的背后,的是一个对自己有极高要求,对理想有极高追求的,不愿意人云亦云,却希望真的在人工智能领域有所作为的科学家的心。在孤独和庸俗,在跟着心走和大流之间,他选择了孤独和跟着心走。
作者: cateyes 时间: 2017-4-15 12:39
本帖最后由 cateyes 于 2017-4-15 12:43 编辑
AlphaGo之父:关于围棋,人类3000年来犯了一个错
http://www.thepaper.cn/baidu.jsp?contid=1660773
2017-04-13 18:43 来源:澎湃新闻 澎湃新闻特约撰稿 刘秀云
阿尔法狗(02:25)
4月10日,“人机大战”的消息再次传出,关于人类和AI的对抗再次牵动世界的神经。
“我会抱必胜心态、必死信念。我一定要击败阿尔法狗!”对于5月23日至27日与围棋人工智能程序AlphaGo(阿尔法狗)的对弈,目前世界排名第一的中国职业九段柯洁放出豪言。然而,AlphaGo(阿尔法狗)之父却说,“我们发明阿尔法狗,并不是为了赢取围棋比赛。”
AlphaGo之父杰米斯·哈萨比斯(Demis Hassabis)近日在母校英国剑桥大学做了一场题为“超越人类认知的极限”的演讲,解答了世人对于人工智能,对于阿尔法狗的诸多疑问——过去3000年里人类低估了棋局哪个区域的重要性?阿尔法狗去年赢了韩国职业九段李世石靠哪几个绝招?今年年初拿下数位国际大师的神秘棋手Master究竟是不是阿尔法狗?为什么围棋是人工智能难解之谜?
杰米斯·哈萨比斯,Deep Mind创始人, AlphaGo之父。
杰米斯·哈萨比斯,Deep Mind创始人,AlphaGo(阿尔法狗)之父, 4岁开始下象棋,8岁时在棋盘上的成功促使他开始思考两个至今令他困扰的问题:第一,人脑是如何学会完成复杂任务的?第二,电脑能否做到这一点?17岁时,哈萨比斯就负责了经典模拟游戏《主题公园》的开发,并在1994年发布。他随后读完了剑桥大学计算机科学学位,2005年进入伦敦大学学院,攻读神经科学博士学位,希望了解真正的大脑究竟是如何工作的,以此促进人工智能的发展。2014年他创办的公司Deep Mind被谷歌收购, 公司产品阿尔法狗在2016年大战围棋冠军李世石事件上一举成名。
哈萨比斯在当天的演讲中透露了韩国棋手李世石去年输给阿尔法狗的致命原因,他最后也提到了阿尔法狗即将迎战的中国棋手柯洁,他说,“柯洁也在网上和阿尔法狗对决过,比赛之后柯洁说人类已经研究围棋研究了几千年了,然而人工智能却告诉我们,我们甚至连其表皮都没揭开。异曲同工,柯洁提到了围棋的真理,我们在这里谈的是科学的真理。”
世界围棋冠军柯洁即将迎战阿尔法狗。
澎湃新闻现场聆听了AlphaGo(阿尔法狗)之父在剑桥大学历时45分钟的演讲,干货满满,请不要漏掉任何一个细节:
非常感谢大家今天能够到场,今天,我将谈谈人工智能,以及DeepMind近期在做些什么,我把这场报告命名为“超越人类认知的极限”,我希望到了报告结束的时候,大家都清晰了解我想传达的思想。
1.你真的知道什么是人工智能吗?
对于不知道DeepMind公司的朋友,我做个简单介绍,我们是在2010年于伦敦成立了这家公司,在2014年我们被谷歌收购,希望借此加快我们人工智能技术的脚步。我们的使命是什么呢?我们的首要使命便是解决人工智能问题;一旦这个问题解决了,理论上任何问题都可以被解决。这就是我们的两大使命了,听起来可能有点狡猾,但是我们真的相信,如果人工智能最基本的问题都解决了的话,没有什么问题是困难的。
那么我们准备怎样实现这个目标呢?DeepMind现在在努力制造世界上第一台通用学习机,大体上学习可以分为两类:一种就是直接从输入和经验中学习,没有既定的程序或者规则可循,系统需要从原始数据自己进行学习;第二种学习系统就是通用学习系统,指的是一种算法可以用于不同的任务和领域,甚至是一些从未见过的全新领域。大家肯定会问,系统是怎么做到这一点的?
其实,人脑就是一个非常明显的例子,这是可能的,关键在于如何通过大量的数据资源,寻找到最合适的解决方式和算法。我们把这种系统叫做通用人工智能,来区别于如今我们当前大部分人在用的仅在某一领域发挥特长的狭义人工智能,这种狭义人工智能在过去的40-50年非常流行。
IBM 发明的深蓝系统(Deep Blue)就是一个很好的狭义人工智能的例子,他在上世纪90年代末期曾打败了国际象棋冠军加里·卡斯帕罗夫(Gary Kasporov) 。如今,我们到了人工智能的新的转折点,我们有着更加先进、更加匹配的技术。
1997年5月,IBM与世界国际象棋冠军加里·卡斯帕罗夫对决。
2.如何让机器听从人类的命令?
大家可能想问机器是如何听从人类的命令的,其实并不是机器或者算法本身,而是一群聪明的编程者智慧的结晶。他们与每一位国际象棋大师对话,汲取他们的经验,把其转化成代码和规则,组建了人类最强的象棋大师团队。但是这样的系统仅限于象棋,不能用于其他游戏。对于新的游戏,你需要重新开始编程。在某种程度上,这些技术仍然不够完美,并不是传统意义上的完全人工智能,其中所缺失的就是普适性和学习性。我们想通过“增强学习”来解决这一难题。在这里我解释一下增强学习,我相信很多人都了解这个算法。
首先,想像一下有一个主体,在AI领域我们称我们的人工智能系统为主体,它需要了解自己所处的环境,并尽力找出自己要达到的目的。这里的环境可以指真实事件,可以是机器人,也可以是虚拟世界,比如游戏环境;主体通过两种方式与周围环境接触;它先通过观察熟悉环境,我们起初通过视觉,也可以通过听觉、触觉等,我们也在发展多感觉的系统;
第二个任务,就是在此基础上,建模并找出最佳选择。这可能涉及到对未来的预期,想像,以及假设检验。这个主体经常处在真实环境中,当时间节点到了的时候,系统需要输出当前找到的最佳方案。这个方案可能或多或少会改变所处环境,从而进一步驱动观察的结果,并反馈给主体。
简单来说,这就是增强学习的原则,示意图虽然简单,但是其中却涉及了极其复杂的算法和原理。如果我们能够解决大部分问题,我们就能够搭建普适人工智能。这是因为两个主要原因:首先,从数学角度来讲,我的合伙人,一名博士,他搭建了一个系统叫‘AI-XI’,用这个模型,他证明了在计算机硬件条件和时间无限的情况下,搭建一个普适人工智能,需要的信息。另外,从生物角度来讲,动物和人类等,人类的大脑是多巴胺控制的,它在执行增强学习的行为。因此,不论是从数学的角度,还是生物的角度,增强学习是一个有效的解决人工智能问题的工具。
3.为什么围棋是人工智能难解之谜?
接下来,我要主要讲讲我们最近的技术,那就是去年诞生的阿尔法狗;希望在座的大家了解这个游戏,并尝试玩玩,这是个非常棒的游戏。围棋使用方形格状棋盘及黑白二色圆形棋子进行对弈,棋盘上有纵横各19条直线将棋盘分成361个交叉点,棋子走在交叉点上,双方交替行棋,以围地多者为胜。围棋规则没有多复杂,我可以在五分钟之内教给大家。这张图展示的就是一局已结束,整个棋盘基本布满棋子,然后数一下你的棋子圈出的空间以及对方棋子圈出的空间,谁的空间大,谁就获胜。在图示的这场势均力敌的比赛中,白棋一格之差险胜。
白棋以一格之差险胜。
其实,了解这个游戏的最终目的非常难,因为它并不像象棋那样,有着直接明确的目标,在围棋里,完全是凭直觉的,甚至连如何决定游戏结束对于初学者来说,都很难。围棋是个历史悠久的游戏,有着3000多年的历史,起源于中国,在亚洲,围棋有着很深的文化意义。孔子还曾指出,围棋是每一个真正的学者都应该掌握的四大技能之一(琴棋书画),所以在亚洲围棋是种艺术,专家们都会玩。
如今,这个游戏更加流行,有4000万人在玩围棋,超过2000多个顶级专家,如果你在4-5岁的时候就展示了围棋的天赋,这些小孩将会被选中,并进入特殊的专业围棋学校,在那里,学生从6岁起,每天花12个小时学习围棋,一周七天,天天如此。直到你成为这个领域的专家,才可以离开学校毕业。这些专家基本是投入人生全部的精力,去揣摩学习掌握这门技巧,我认为围棋也许是最优雅的一种游戏了。
像我说的那样,这个游戏只有两个非常简单的规则,而其复杂性却是难以想象的,一共有10170 (10的170次方) 种可能性,这个数字比整个宇宙中的原子数1080(10的80次方)都多的去了,是没有办法穷举出围棋所有的可能结果的。我们需要一种更加聪明的方法。你也许会问为什么计算机进行围棋的游戏会如此困难,1997年,IBM的人工智能DeepBlue(深蓝)打败了当时的象棋世界冠军加里·卡斯帕罗夫,围棋一直是人工智能领域的难解之谜。我们能否做出一个算法来与世界围棋冠军竞争呢?要做到这一点,有两个大的挑战:
一、搜索空间庞大(分支因数就有200),一个很好的例子,就是在围棋中,平均每一个棋子有两百个可能的位置,而象棋仅仅是20. 围棋的分支因数远大于象棋。
二、比这个更难的是,几乎没有一个合适的评价函数来定义谁是赢家,赢了多少;这个评价函数对于该系统是至关重要的。而对于象棋来说,写一个评价函数是非常简单的,因为象棋不仅是个相对简单的游戏,而且是实体的,只用数一下双方的棋子,就能轻而易举得出结论了。你也可以通过其他指标来评价象棋,比如棋子移动性等。
所有的这些在围棋里都是不可能的,并不是所有的部分都一样,甚至一个小小部分的变动,会完全变化格局,所以每一个小的棋子都对棋局有着至关重要的影响。最难的部分是,我称象棋为毁灭性的游戏,游戏开始的时候,所有的棋子都在棋盘上了,随着游戏的进行,棋子被对方吃掉,棋子数目不断减少,游戏也变得越来越简单。相反,围棋是个建设性的游戏,开始的时候,棋盘是空的,慢慢的下棋双方把棋盘填满。
因此,如果你准备在中场判断一下当前形势,在象棋里,你只需看现在的棋盘,就能告诉你大致情况;在围棋里,你必须评估未来可能会发生什么,才能评估当前局势,所以相比较而言,围棋难得多。也有很多人试着将DeepBlue的技术应用在围棋上,但是结果并不理想,这些技术连一个专业的围棋手都打不赢,更别说世界冠军了。
所以大家就要问了,连电脑操作起来都这么难,人类是怎样解决这个问题的?其实,人类是靠直觉的,而围棋一开始就是一个靠直觉而非计算的游戏。所以,如果你问一个象棋选手,为什么这步这样走,他会告诉你,这样走完之后,下一步和下下一步会怎样走,就可以达到什么样的目的。这样的计划,有时候也许不尽如人意,但是起码选手是有原因的。
然而围棋就不同了,如果你去问世界级的大师,为什么走这一步,他们经常回答你直觉告诉他这么走,这是真的,他们是没法描述其中的原因的。我们通过用加强学习的方式来提高人工神经网络算法,希望能够解决这一问题。我们试图通过深度神经网络模仿人类的这种直觉行为,在这里,需要训练两个神经网络,一种是决策网络,我们从网上下载了成百万的业余围棋游戏,通过监督学习,我们让阿尔法狗模拟人类下围棋的行为;我们从棋盘上任意选择一个落子点,训练系统去预测下一步人类将作出的决定;系统的输入是在那个特殊位置最有可能发生的前五或者前十的位置移动;这样,你只需看那5-10种可能性,而不用分析所有的200种可能性了。
一旦我们有了这个,我们对系统进行几百万次的训练,通过误差加强学习,对于赢了的情况,让系统意识到,下次出现类似的情形时,更有可能做相似的决定。相反,如果系统输了,那么下次再出现类似的情况,就不会选择这种走法。我们建立了自己的游戏数据库,通过百万次的游戏,对系统进行训练,得到第二种神经网络。选择不同的落子点,经过置信区间进行学习,选出能够赢的情况,这个几率介于0-1之间,0是根本不可能赢,1是百分之百赢。
通过把这两个神经网络结合起来(决策网络和数值网络),我们可以大致预估出当前的情况。这两个神经网络树,通过蒙特卡洛算法,把这种本来不能解决的问题,变得可以解决。我们网罗了大部分的围棋下法,然后和欧洲的围棋冠军比赛,结果是阿尔法狗赢了,那是我们的第一次突破,而且相关算法还被发表在《自然》科学杂志。
接下来,我们在韩国设立了100万美元的奖金,并在2016年3月,与世界围棋冠军李世石进行了对决。李世石先生是围棋界的传奇,在过去的10年里都被认为是最顶级的围棋专家。我们与他进行对决,发现他有非常多创新的玩法,有的时候阿尔法狗很难掌控。比赛开始之前,世界上每个人(包括他本人在内)都认为他一定会很轻松就打赢这五场比赛,但实际结果是我们的阿尔法狗以4:1获胜。围棋专家和人工智能领域的专家都称这具有划时代的意义。对于业界人员来说,之前根本没想到。
4.棋局哪个关键区域被人类忽视了?
这对于我们来说也是一生仅有一次的偶然事件。这场比赛,全世界28亿人在关注,35000多篇关于此的报道。整个韩国那一周都在围绕这个话题。真是一件非常美妙的事情。对于我们而言,重要的不是阿尔法狗赢了这个比赛,而是了解分析他是如何赢的,这个系统有多强的创新能力。阿尔法狗不仅仅只是模仿其他人类选手的下法,他在不断创新。在这里举个例子 ,这是第二局里的一个情况,第37步,这一步是我整个比赛中最喜欢的一步。在这里,黑棋代表阿尔法狗,他将棋子落在了图中三角标出的位置。为什么这步这么关键呢?为什么大家都被震惊到了。
图左:第二局里,第37步,黑棋的落子位置 图右:之前貌似陷入困境的两个棋子。
其实在围棋中有两条至关重要的分界线,从右数第三根线。如果在第三根线上移动棋子,意味着你将占领这个线右边的领域。而如果是在第四根线上落子,意味着你想向棋盘中部进军,潜在的,未来你会占棋盘上其他部分的领域,可能和你在第三根线上得到的领域相当。
所以在过去的3000多年里,人们认为在第三根线上落子和第四根线上落子有着相同的重要性。但是在这场游戏中,大家看到在这第37步中,阿尔法狗落子在了第五条线,进军棋局的中部区域。与第四根线相比,这根线离中部区域更近。这可能意味着,在几千年里,人们低估了棋局中部区域的重要性。
有趣的是,围棋就是一门艺术,是一种客观的艺术。我们坐在这里的每一个人,都可能因为心情好坏产生成千上百种的新想法,但并不意味着每一种想法都是好的。而阿尔法狗却是客观的,他的目标就是赢得游戏。
5.阿尔法狗拿下李世石靠哪几个绝招?大家看到在当前的棋局下,左下角那两个用三角标出的棋子看起来好像陷入了困难,而15步之后,这两个棋子的力量扩散到了棋局中心,一直延续到棋盘的右边,使得这第37步恰恰落在这里,成为一个获胜的决定性因素。在这一步上阿尔法狗非常具有创新性。我本人是一个很业余的棋手,让我们看看一位世界级专家Michael Redmond对这一步的评价。 Michael是一位9段选手(围棋最高段),就像是功夫中的黑段一样,他说:“这是非常令人震惊的一步,就像是一个错误的决定。”在实际模拟中,Michael其实一开始把棋子放在了另外一个地方,根本没想到阿尔法狗会走这一步。像这样的创新,在这个比赛中,阿尔法狗还有许多。在这里,我特别感谢李世石先生,其实在我们赢了前三局的时候,他下去了。
2016年3月阿尔法狗大战世界围棋冠军李世石,以4:1的总分战胜了人类。
那是三场非常艰难的比赛,尤其是第一场。因为我们需要不断训练我们的算法,阿尔法狗之前打赢了欧洲冠军,经过这场比赛,我们知道了欧洲冠军和世界冠军的差别。理论上来讲,我们的系统也进步了。但是当你训练这个系统的时候,我们不知道有多少是过度拟合的,因此,在第一局比赛结束之前,系统是不知道自己的统计结果的。所以,其实第一局,我们非常紧张,因为如果第一局输了,很有可能我们的算法存在巨大漏洞,有可能会连输五局。但是如果我们第一局赢了,证明我们的加权系统是对的。
不过,李世石先生在第四场的时候,回来了,也许压力缓解了许多,他做出了一步非常创新性的举动,我认为这是历史上的创新之举。这一步迷惑了阿尔法狗,使他的决策树进行了错误估计,一些中国的专家甚至称之为“黄金之举”。通过这个例子,我们可以看到多少的哲理蕴含于围棋中。这些顶级专家,用尽必生的精力,去找出这种黄金之举。其实,在这步里,阿尔法狗知道这是非常不寻常的一步,他当时估计李世石通过这步赢的可能性是0.007%,阿尔法狗之前没有见过这样的落子方式,在那2分钟里,他需要重新搜索决策计算。我刚刚已经提到过这个游戏的影响:28亿人观看,35000相关文章的媒体报道,在西方网售的围棋被一抢而空,我听说MIT(美国麻省理工学院)还有其他很多高校,许多人新加入了围棋社。
第四局里,李世石第78步的创新之举。
我刚才谈到了直觉和创新,直觉是一种含蓄的表达,它是基于人类的经历和本能的一种思维形式,不需要精确计算。这一决策的准确性可以通过行为进行评判。在围棋里很简单,我们给系统输入棋子的位置,来评估其重要性。阿尔法狗就是在模拟人类这种直觉行为。创新,我认为就是在已有知识和经验的基础上,产生一种原始的,创新的观点。阿尔法狗很明显的示范了这两种能力。
6.神秘棋手Master究竟是不是阿尔法狗?
那么我们今天的主题是“超越人类认知的极限”,下一步应该是什么呢?从去年三月以来,我们一直在不断完善和改进阿尔法狗,大家肯定会问,既然我们已经是世界冠军了,还有什么可完善的? 其实,我们认为阿尔法狗还不是完美的,还需要做更多的研究。
首先,我们想要继续研究刚才提到的和李世石的第四局的比赛,来填充知识的空白;这个问题其实已经被解决了,我们建立了一个新的阿尔法狗分系统,不同于主系统,这个分支系统是用来困惑主系统的。我们也优化了系统的行为,以前我们需要花至少3个月来训练系统,现在只需要一周时间。
第二,我们需要理解阿尔法狗所采取的决定,并对其进行解释;阿尔法狗这样做的原因是什么,是否符合人类的想法等等;我们通过对比人类大脑对于不同落子位置的反应以及阿尔法狗对于棋子位置的反应,以期找到一些新的知识;本质上就是想让系统更专业。我们在网络上与世界顶级的专家对决,一开始我们使用了一个假名(Master),在连胜之后被大家猜出是阿尔法狗。这些都是顶级的专家,我们至今已赢了60位大师了。如果你做个简单的贝叶斯分析,你会发现阿尔法狗赢不同对手的难易也不一样。而且,阿尔法狗也在不断自我创新,比如说图中右下角这个棋子(圆圈标处),落在第二根线里,以往我们并不认为这是个有效的位置。实际上,韩国有的团队预约了这些游戏,想研究其中新的意义和信息。
阿尔法狗自我创新,落在第二格线的旗子。
柯洁,既是中国的围棋冠军,也是目前的世界围棋冠军,他才19岁。他也在网上和阿尔法狗对决过,比赛之后他说人类已经研究围棋研究了几千年了,然而人工智能却告诉我们,我们甚至连其表皮都没揭开。他也说人类和人工智能的联合将会开创一个新纪元,将共同发现围棋的真谛。异曲同工,柯洁提到了围棋的真理,我们在这里谈的是科学的真理。
红遍网络的神秘棋手Master2017年1月3日在腾讯围棋对弈平台赢了柯洁。
Master执白中盘胜柯洁,Master就是AlphaGo的升级版。
那么围棋的新纪元是否真的到来了呢?围棋史上这样的划时代事件曾经发生过两次,第一次是发生在1600年左右的日本,20世纪30-40年代的日本,日本一位当时非常杰出的围棋高手吴清源提出了一个全新的关于围棋的理论,将围棋提升到了一个全新的境界。大家说如今,阿尔法狗带来的是围棋界的第三次变革。
7.为什么人工智能“下围棋”强于“下象棋”?
我想解释一下,为什么人工智能在围棋界所作出的贡献,要远大于象棋界。如果我们看看当今的世界国际象棋冠军芒努斯·卡尔森,他其实和之前的世界冠军没什么大的区别,他们都很优秀,都很聪明。但为什么当人工智能出现的时候,他们可以远远超越人类?我认为其中的原因是,国际象棋更注重战术,而阿尔法狗更注重战略。如今世界顶级的国际象棋程序再不会犯技术性的错误,而在人类身上,不可能不犯错。第二,国际象棋有着巨大的数据库,如果棋盘上少于9个棋子的时候,通过数学算法就可以计算出谁胜谁败了。计算机通过成千上万的迭代算法,就可以计算出来了。因此,当棋盘上少于九个棋子的时候,下象棋时人类是没有办法获胜的。
因此,国际象棋的算法已经近乎极致,我们没有办法再去提高它。然而围棋里的阿尔法狗,在不断创造新的想法,这些全新的想法,在和真人对决的时候,顶级的棋手也可以把其纳入到考虑的范畴,不断提高自己。
就如欧洲围棋冠军樊麾(第一位与阿尔法狗对阵的人类职业棋手)所说的那样,在和阿尔法狗对决的过程中,机器人不断创新的下法,也让人类不断跳出自己的思维局限,不断提高自己。大家都知道,经过专业围棋学校里30多年的磨练,他们的很多思维已经固化,机器人的创新想法能为其带来意想不到的灵感。我真的相信如果人类和机器人结合在一起,能创造出许多不可思议的事情。我们的天性和真正的潜力会被真正释放出来。
8.阿尔法狗不为了赢取比赛又是为了什么?
就像是天文学家利用哈勃望远镜观察宇宙一样,利用阿尔法狗,围棋专家可以去探索他们的未知世界,探索围棋世界的奥秘。我们发明阿尔法狗,并不是为了赢取围棋比赛,我们是想为测试我们自己的人工智能算法搭建一个有效的平台,我们的最终目的是把这些算法应用到真实的世界中,为社会所服务。
当今世界面临的一个巨大挑战就是过量的信息和复杂的系统,我们怎么才能找到其中的规律和结构,从疾病到气候,我们需要解决不同领域的问题。这些领域十分复杂,对于这些问题,即使是最聪明的人类也无法解决的。
我认为人工智能是解决这些问题的一个潜在方式。在如今这个充斥着各种新技术的时代,人工智能必须在人类道德基准范围内被开发和利用。本来,技术是中性的,但是我们使用它的目的和使用它的范围,大大决定了其功能和性质,这必须是一个让人人受益的技术才行。
我自己的理想是通过自己的努力,让人工智能科学家或者人工智能助理和医药助理成为可能,通过该技术,我们可以真正加速技术的更新和进步。(本文作者系英国剑桥大学神经学博士生,AlphaGo之父哈萨比斯在剑桥大学的校友,文章小标题系编者所注)
作者: hidear 时间: 2017-4-15 18:33
Thanks for sharing! 
作者: cateyes 时间: 2017-5-30 15:08
http://sports.sina.com.cn/go/2017-05-30/doc-ifyfqvmh9531628.shtml陈经:从人机大战看中美人工智能竞争态势
2017年05月30日10:23 新浪体育 微博
陈经
2017年5月27日
(5月27日在上海,我在观察者网举办的观天下论坛讲了人机大战、人工智能的误解、中美竞争等问题,并回答了现场观众提问。观察者网和Bilibili有视频直播。本文为文字整理版,首发于观察者网:观天下讲坛|柯洁战败了,中国AI技术距离世界第一还有多远?)

大家好,我今天要讲的是人工智能与人工智能的热潮。
我是计算机专业出身,也是做人工智能研发的。在历史上,人工智能从来没有这么火过,它的根源就是因为去年AlphaGo的横空出世,现在适逢其会,今天10点半柯洁就要和AlphaGo进行第三局比赛,这是很多人都很关注的,但我今天要讲的不仅是围棋,还包括人工智能。
人工智能对社会的方方面面都有影响,但是人工智能这么热,也带来了一个问题,就是社会对人工智能有很多误解,所以今天我也要讲一下如何正确理解人工智能;另外一个方面,人工智能热潮对我们中国是很有利的,中国在人工智能行业的积累是很不错的,应该说中国和美国在人工智能行业是遥遥领先的。中国和美国比较的话,差距在哪里?中国有没有可能挑战美国?相信大家对这些都会很感兴趣。
柯洁全负,但证明了他是人类最强棋手实至名归
柯洁和AlphaGo对局,目前是0:2落后。如果柯洁能以2:1获胜的话,他的奖金将高达1000万人民币,这是围棋史上最高的一笔奖金,但是赛前大家都不相信柯洁能拿到这笔钱。我感觉第二局已经是柯洁实力发挥的巅峰了,第三局如果他能创造奇迹达到1:2的战绩,那将是人类的一个超级大胜利。但是我理智地预测的话他应该会0:3告负,虽然他第三局要求执白,柯洁比较擅长执白。
去年3月份李世石对战AlphaGo,李世石是赢了一局,这对人类棋手来说已经是非常大的鼓励了。如果当时0:5告负,那现在的气氛会完全不一样。那么李世石赢过一盘,柯洁全负,是不是就可以说柯洁不如李世石?我可以明确地告诉大家柯洁的表现远远好于李世石。为什么?因为根据Deepmind发布的信息,现在这个版本的AlphaGo能够让李世石那时的AlphaGo三子,这个在懂围棋的职业棋手看来,简直是一个天大的差距,简直不敢相信,但真的就这样发生了。
柯洁能和这么强大的AlphaGo战得如此难解难分,那么跟李世石相比他的表现确实要好很多,这是围棋专业人士一致认同的。这次即使柯洁0:3告负,也能够给人们留下深刻的印象:柯洁是人类最强棋手。因为下图这个局面就能够看出来,这是5月25号柯洁与AlphaGo第二局。不懂围棋的没关系,我来形容一下。AlphaGo以前化名Master在网络上和人类高手混战60局,全胜。在60局里,还没有一局达到过这个混乱程度。

之前我在文章中说,要制造混乱的、复杂的局面,才有机会。但是以前的人想混乱都混乱不起来,想复杂也复杂不起来,Master使出简简单单几个招数,人类棋手就不行了,50手就不行了。没有任何棋手和AlphaGo达到过这种局面,柯洁在前100手表现完美,达到了一个其他棋手不敢想象的局面。我跟应氏杯冠军唐韦星一起直播过棋赛,我跟他也讨论过这个制造混乱的战术,他说我们想混乱,但是没有那个能力。但是柯洁证明自己有这个能力,所以棋手们都服气了,都认同柯洁是人类棋手中最强的。
即使这样,是不是就说柯洁有机会战胜AlphaGo了呢?我还不敢这么说。柯洁自己在第二局结束后的采访中说当时真实地感觉有胜机,心怦怦地乱跳。但局后我们冷静下来,包括一些职业棋手去摆棋做分析,认为AlphaGo根本没有给柯洁胜机,即使面对这么复杂的局面,AlphaGo仍然在掌控之中。
经过第二局,以及昨天的“五人打狗”,我相信基本上没有人不服气了,AlphaGo确实已经超过了人类棋手,只是差距有多大而已。我之前写了很多文章,核心思想就是如何战胜AlphaGo,构想了很多招数,但是现在我觉得应该放弃这个思想了。

为什么棋手和研究人工智能的都服气了呢?因为伴随着人工智能的技术突破,它确实已经从原理上让人服气了。一方面是战绩,和人类最强棋手3:0全胜;另外一方面,从学术角度看,人工智能领域有一个深度学习,就像前面讲到的深度神经网络,它是模仿人脑的。比如说腾讯和Deepmind有很多服务器,10万服务器生成一大堆数据,这都是以前没法想象的,然后又通过模拟人类的思维方式实现自我训练。这里涉及的技术细节太多了,我在观察者网发表的一系列文章里头有介绍,大家可以去看。
而且,人总是有缺陷的,有时候发挥很好,但是偶然出了一个错招,那也没办法。即使最厉害的职业棋手,也会犯错。但是机器是永远稳定发挥的,不会出简单的错招,如果出了错,也是属于算法这一非常深层次的原因。所以机器相对于人的优势是没有办法的事,而且它以后水平可能越来越高,而人年纪大了,水平就下降了。
对人工智能的误解
现在人工智能这么热,导致我们对它产生了很多误解,我具体说一下都有哪些误解。
第一个,很多人说围棋这么复杂的一个游戏,居然人赢不了机器,这下完了,AI崛起了,又出了一个新物种,人类要毁灭了……这个实际上过于夸张了,甚至连开这个玩笑的人自己都不相信吧,只是一种科幻的念头。
第二个,大家老是把人工智能想象成一个人。下面这个图是中国科技大学做的机器人“佳佳”,其实就是一个聊天机器人,它也可以是一个电脑,但是偏偏把它造成了人的模样。我觉得这是蒙人,它长什么样子根本没关系,美女的想象纯粹是为了抓眼球。现在人工智能跟人的外貌毫无关系,它其实就是一些程序,没有任何自己的思想,我们称之为弱人工智能。

第三,人工智能崛起了,机器人不仅在体力劳动上比人类强,连智力都要战胜人类了。那以后人类大量工作都被机器人取代了,以后我们怎么生活啊?体力劳动者做不成,智力工作者也不好干了。这个其实也是在吓唬人,我一会再详细解释。
IT是母行业,人工智能是子行业
这个是硅谷推出的IT业新技术的曲线发展图。这个顶点不是技术最高,而是社会对技术的期望达到最高值了。大家觉得这个技术非常值钱或者说无所不能,各种风投都一扑而上,直接投钱。

这是2014年的图,那时候没有机器学习,人工智能也不是太热,热的是大数据和物联网。按照技术规律,热了之后,因为人夸张了它的能力,大家发现它没那么厉害,有些人就撤了,它就会进入一个低谷期。但像我这样的人工智能或者说是计算机研发者会努力突破一些技术障碍,突破低谷期,又进入复苏期、成熟期,这是一个正常的发展规律。
下面是2016年的曲线发展图。这个时候我们发现最热的是机器学习,也代表2016年的人工智能热,完全是因为人机大战、AlphaGo激发出来的。而且这张图还不足够彻底展现机器学习的热度,如果完全呈现出来这张图就爆表了,还没有任何技术的热度超过机器学习的。但是我们冷静下来看,机器学习或者说人工智能还是会碰到低谷期的,不是说它就会一直这么热下去。

为什么人工智能在中国这么热门呢?因为人工智能在中国发展状态是很好的。美国在人工智能领域的技术是最好的,中国可以排第二,以后也只主要是中国和美国竞争。
我一直在搞算法,但我不会觉得自己是一个做人工智能的,向别人介绍时我会说我是干IT的。以前我们会说人工智能革命改造世界,这完全属于夸张。IT业是真正在改造世界,而且不是要改造世界,而是真的已经在改变世界了。看看我们这些年生活发生这么大的变化,主要都是IT带来的。我们说三次工业革命,而这第三次工业革命最大的动力就是IT,人工智能其实只是属于IT行业里头的一个子行业。
如果说一个IT从业人员跳槽到人工智能领域,不会感觉到有什么大的隔阂。IT这么多年就没有低谷,从三四十年前有了IT业到现在从来都缺人,工资也在不断地加,跟其他行业的工资差距越来越大。人工智能以前火过一阵子,比如日本的第五代计算机,但是那次第五代计算机失败了,人工智能也进入了低潮。从另一角度来看,也是因为IT业太火了,反衬出人工智能进入瓶颈,其实一直以来人工智能的热潮都是IT行业在推动。但接下来我预测人工智能可能会进入低潮。
中美在人工智能领域的竞争与优势
为什么我说未来人工智能领域是中美竞争呢?这张表是20个IT大公司的市值排名,里面全是美国和中国的公司,只有一个日本Yahoo,但Yahoo还是美国的。而人工智能又是IT的子行业,所以人工智能领域必然是中美竞争。前两次工业革命,中国都是落后的。但是在IT引领的工业革命,中国自2000年后迅速崛起,其中IT是一个重要的工具。有IT,中国实现了跨越式成长。

除了刚才所讲的宏观方面,还有一些具体的例证。下图是关于深度学习领域的论文,可以看出中国和美国的论文数量遥遥领先于其他国家,也就是说从研发的角度,中美也是遥遥领先。

我们再从围棋AI来看,可以说最厉害的就是AlphaGo,第二名是腾讯开发的绝艺,第三名是一个日本的程序DeepZenGo。3月份在日本有一个UEC杯,30多个人工智能程序互相比赛。绝艺两次战胜DeepZenGo,夺得冠军。AlphaGo没有参赛,因为觉得其他都太弱了。总之,这个名次是得到公认的。
中美在围棋AI也是竞争关系,腾讯投入三个团队开发绝艺,淘汰了两个,剩下的一个胜出。这个投入是非常大的,为了训练绝艺,让它下了30亿局棋,光是投入的服务器就不计其数。相比之下,日本DeepZenGo的开发者抱怨得到的支持太少了,太穷了,所以日本的围棋AI虽然也能够和职业棋手比赛,但是明显投入不足,落后于中美。AlphaGo背靠大公司,绝艺背后的腾讯市值也不低,我估计腾讯以后会是中国市值最大的一个公司,现在是不是已经最大了需要再确认一下,反正在港股是最大的市值。
据我观察,绝艺的开发也进入瓶颈期了,它跟职业棋手比赛总是会输,比如十盘会输两盘,我感觉绝艺跟AlphaGo还是有很大差距的。但是之后绝艺会不会有进步呢?一定会。因为马上AlphaGo团队会公布新版本的技术秘密,去年他们发表在Nature的文章把所有的技术细节都公布了,今年6月份会再发一篇文章,公布主要的技术细节。我相信看过“武功秘籍”后就会知道他们是怎么做的,绝艺团队现在应该已经在用新思想开发了,我估计不用太久绝艺就可以取得技术突破,慢慢就跟AlphaGo一样,对战人类棋手不可能输了。
中国能不能在人工智能领域挑战美国?我觉得是有可能的。中美双方各有所长。
第一,美国原创研发能力极强,中国应用研发可以做到指标最高。我非常佩服美国的原创研发能力,在它做出这个原创研发之前,大家都想不到居然会有一个程序,能够在这么短的时间内就把围棋攻破了,之前预测都是十年、二十年,甚至有上百年。中国的优势是很多IT公司的应用做得非常好,比如语音识别、人脸识别的正确率指标比较高。中美两国对研发的导向不太相同,有批评者说中国的原创研发太少了,我觉得这也不能说完全就是劣势,只是双方各有特点。

第二,美国吸引世界人才,中国自己培养海量人才。美国能够招到全世界最优秀的研发人才,但中国也不怕。因为中国人口多,人才数量已经足够了,而且现在信息交流这么发达,美国发表的先进的研究思想,全世界都能第一时间看到。
第三,美国产品天然面向全世界,中国市场同样大。英语有全球优势,美国推出的产品很快就能遍布全球。但中国自身市场就很大,人口比发达国家总数还多,如果开发好了丝毫不弱于美国的市场。
第四,“美国设计,中国与制造业产业链紧密结合”其实是中国优势,因为美国基本没有生产。苹果鼓吹多厉害,设计研发多好,但是中国华为等很多公司和产业紧密联系在一起。研发东西,除了原创,还需经历落地的过程。不能只发论文不管后续,要根据研究论文做出智能产品,人们才能理解那些高深论文在讨论什么。而中国,在应用和产业链方面具有优势。
所以,我在写文章以及和朋友聊天时,都强调不要唱衰美国,当然更不能唱衰中国。中国和美国在以后都会发展得不错,中国和美国相对于其他国家优势会越来越大。
为什么说人工智能天生可能会陷入低潮
我们常听到“这神奇的科技,了不得”。意义很大的未来科技我总结有三个,一是可控核聚变,二是量子计算机,还有一个是强人工智能。这三个科技讲了很多年,都是很困难的。
50年前,科学家就告诉大家,50年后大家就能用上核聚变能源了。但是现在还未实现,说还要40年,其实就是基础问题没解决。量子计算机现在有很多实验性的突破,但是物理上极困难,特别不稳定,量子比特容易破坏。而强人工智能,也就是机器有自我意识,我认为比前两个靠谱点,因为至少计算机操作是稳定的,但在算法上怎么发展,还是没招。
所以,要从基础考察的话,这些未来科技不牢靠,只能是幻想。也可能出现突破,只是不一定。
IT火了这么多年,其实从基础上考察的话,我们会发现,IT的基础特别牢靠。硬件基础方面,计算机的逻辑门极可靠,从来不出错。摩尔定律、越来越大的存储等,都是基础好的缘故。
其实只有一小撮人搞硬件基础,而软件基础,是很多程序员写代码、算法。写代码、算法有一个特性,就是要无漏洞。代码出错,必须要改正确了。所以,他们推崇的精神就是代码要靠谱。程序员不能忽悠机器,所以特征是靠谱。
IT为什么这么火,我认为就是基础特别好,无论是软件还是硬件基本不会出错,有错误我们也可调试改正。我为什么觉得人工智能会陷入低潮?因为人工智能不可靠。
现在吹说机器学习厉害,说学习正确率越来越高,超过人的能力。比如100万张图片里找十个人,人可能找不出,而机器能有百分之七八十的概率找到。再比如语音识别正确率也跟人接近。但是,它不精确,即使指标达到95%或者更高,不精确还是会出错。IT出了错有办法调试,而机器学习是内在错误,不可能消除。所以,它天生有点不靠谱。
说AlphaGo等人工智能会战胜人类,那是人类受生理条件的限制。人类本身有各种各样的缺陷,因此战胜人不是一件特别了不起的事。汽车比博尔特跑得快,那不是很正常的事?人类会犯错,而机器稳定,因此有些事超过人很正常。
但是,人类有很厉害的能力,是机器绝对比不了的。比如,人类会搞科研,而机器不行。不能光说人类不行,还得强调人比机器强在哪儿。人类互相合作就会扎根生长,而机器最大的问题是没有思想——思想能够产生各种灿烂的文明,各种科技都是人类的思想。在强人工智能出现之前,现在的机器离人类文明差太远了。
我现在对聊天机器人的评价是,它们根本不懂我们在聊什么,但是会抓住你言语中的一个词关联其他事物,其实并不理解对话是怎么回事儿。作诗机也是在蒙人,它根本不知道自己在写什么,只是把“玩具”、“床”等词汇换成1234,再13535等词一堆,就这么出来了。是人给作品赋予了意义,而不是机器。再比如与柯洁下围棋的AlphaGo,机器是不知道自己的棋谱有多厉害的,而人知道,能从中解读出AlphaGo的实力有多强。DeepMind公司说与人类一同探索棋艺的奥妙,这不是谦虚的话。

现在人工智能比较火的还有自动驾驶。最近百度把自动驾驶开发包公开,说是促进社会共同研发人工智能自动驾驶,自己不干或不全力去干了。我个人认为,这是因为自动驾驶太难了。机器下棋是一个单纯的事件,在绝对单一的场景里,目的设定非常清楚,而自动驾驶面临的各种条件太复杂。谷歌、特斯拉的自动驾驶在美国开得还不错,但放到中国,得重新开发。换了一个场景就不行了,这是人工智能的问题。
我自己是搞人工智能的,所以我知道人工智能的特性是不靠谱,要非常小心,不能认为它超过人。可以用它去做事,但是得事先做好它不靠谱后要怎么办的预防。
人工智能为什么现在这么火?观察生活,会发现有些人工智能已很靠谱。如车牌识别已是很成熟的技术,在这个行业已一统天下。我相信以后在停车场停车会是无人管理,用软件、算法去解决,这是因为车牌识别的准确率已超过人了,也超过了RFID等硬件。突破一个指标,就可以取代人,但这种行业还不太多。
说人工智能一个程序搞定一切,绝对是不对的,因为社会生活包括方方面面,人工智能目前只能干单一的任务。把单一的任务嵌入社会生活过程中,才能起到作用。
比如送快递,人人都能干,没有学历等要求。但要让一个人工智能机器人去送快递,这事不靠谱。因为送快递有很多步骤,如要识字、跑腿、上楼等,人工智能只能在分发、条形码扫描等某个步骤做事,不可能全程包揽。现在的微信、支付宝支付,用二维码识别,人工智能的识别率非常高,但是我不承认这是人工智能对社会革命化改造。我只承认,这是IT化对社会的改造,主要还是IT大公司的贡献。
人工智能行业中国赶超美国的机会
人工智能行业,中美两国排名前两,其他国家无法与之抗衡。而中美两国,哪个更有机会?我个人认为有两种情况:
第一种情况,现在人工智能被说得上天入地很神奇,但是过两年大家会发现要想取得进展不容易。这样,它就会从过热期进入低谷期,那时研发者估计会偏保守点,就是我能干的事去干,不能干的不干。进入低谷期,就是中国的拿手好戏了,我称之为“白菜化”。为什么中国在世界的经济影响力这么大?那是因为中国把很多行业的高科技都给“白菜化”了,人工智能也逃不脱这一命运。
如果人工智能的研发进入低谷期,高水平的研发人员就无用武之地了。(当然,积极搞强人工智能突破是另一回事。)当其一旦进入瓶颈,中国的优势就会显现。举个例子。 今年一月,我在微博上推荐过一支股票——海康威视。那时股价为25,现在26元。但是它期间除权了一次,十送六,所以它的价格其实上涨了60%多。在现在股市大跌的情况下,海康威视已变成深市的第一大股了,市值接近2000亿,超过万科。海康威视为什么能增长这么多?

海康威视不是搞人工智能的,而是世界上最大的摄像头生产商,是德州仪器芯片、索尼CCD等部件的最大客户。所以,海康威视的所有元件成本是世界最低的,生产摄像头的成本是一般厂家的70%。海康威视用30%的成本优势发展技术,如人脸识别、车牌识别等技术,还全部不要钱,白送。其摄像头就是一人工智能产品。人脸识别创业企业在2014~2016年市场估值一度很高,但是海康威视招人来干人脸识别就行了,要转型成人工智能企业,有很大的优势,这也是其市值变成深市第一名的原因。
这例子对中国也是有用的。“白菜化”,包含生产、研发两阶段。现在中国各生产企业都在疯狂招搞人工智能的人,和生产结合一块儿,生产人工智能产品,从而改造社会。我相信,人工智能要改造全球,不是美国去推动,而是中国。因为改造全球的不是论文,而是具体的产品,而产品是中国的优势。按这图景,我相信未来人工智能行业,中国会因应用做得最好,而超过美国。
第二种情况,如强人工智能被研发出来,可以取代人的工作。很多人的工作危险、辛苦、无聊,如果机器能做是很好的事。还有稀缺的如专家医生,如果人工智能可以成为医疗专家,对排队等专家治病的广大群众而言是一件好事。如果人工智能真有这些本事,就是人工智能革命,而非IT革命。那时社会生产力将急剧发展,翻十倍都可以想象。人要做的工作将减少,底层福利又上升。
中国在这些好的图景上是有优势的,因为中国国家体制是社会主义,一旦人工智能对社会造成巨大冲击,国家政府有能力照顾大众的利益,而不只是大公司的利益。如有公司研发出超级厉害的人工智能,抢占了所有工作,国家是会想办法对其进行限制的。外国特别注重公司权益,按照谁投入谁收获的原则,人工智能福利会不会传给大众要扯皮。 机器代替人类工作,人没工作是否要完蛋?不是的。人类社会会进行调整,如搞机器共产主义。某公司研发很厉害的机器人,可以替代众多人的工作,人们可以要求立法,关于这一机器人的收益,研发公司收10%,90%归政府,政府再分给个人。再比如,人缺乏工作能力,政府派两机器仆人帮赚钱去,那人整天打游戏就行。机器人特别听话,特别有执行力,那就可以大搞计划经济了。
相信若出现人工智能大发展,中国社会变革能力是能够领先美国的,中国搞改革是本能。在这一情况下,我相信中国人民的福利会得到大幅度提升。当然,这一情况不是必然的,还只是一种美梦。至于说人工智能替代人,这是在吓唬人,人类社会还是很能适应变革与发展的。
作者: cateyes 时间: 2017-5-30 15:10
http://sports.sina.com.cn/go/2017-05-30/doc-ifyfqvmh9530669.shtml
AlphaGo的强大远超人类 该放弃击败它的想法了2017年05月30日10:15 新浪体育 微博分享|评论13
 中国5将团灭
中国5将团灭 陈经
2017年5月27日
(本文首发于观察者网:如何战胜AlphaGo?该放弃这想法了)
2017年5月27日,柯洁在与AlphaGo的最后一局中执白发挥不佳,最后求投场大龙被吃负于AlphaGo,人机大战0:3没有取得突破。
在前一天的人机配对赛中(前一天文章我以为是人参考AlphaGo提供的选点下,其实不是,配对赛人机虽然是一边但是不商量,轮流各下一手),连笑与AlphaGo执白战胜了古力与AlphaGo,比赛中人类棋手明显发挥更差,导致棋局缺少逻辑状况不断不够流畅。女棋手唐奕透露说,古力一方本来胜率高达75%胜定(由于之前连笑的错着),古力一招错棋胜率降成60%,再一招掉成45%,后来继续犯错被翻盘。人机联棋,人类高手的表现明显差于AlphaGo,就象人类混双赛中女棋手的表现。

同一天唐韦星等五位中国世界冠军以相谈棋(五人商量着下)的形式执黑对战AlphaGo,第一个接触战就早早出败着。猜到自认为不利的黑棋后,五位高手心态受影响,27手长过于松垮,在这个局部地势全失,早早就陷入困境。整盘棋早早进入了AlphaGo的控制流,它开始标志性地不断送目。棋手们眼看又要以最小差距负,干脆中盘认负,最大的贡献可能是一个神同步的表情包。
今天第三局柯洁执白不是猜先的,是第二局后他主动要求的,更利于第三局发挥水平。柯洁2015年执白全年只负一局,他的白棋可以说代表了人类高手的最高水平。但本局还是较早阶段就出了败招,以较大差距负于AlphaGo,发挥可能还不如第一局。
二次人机大战五盘棋结束,应该可以得出结论了:AlphaGo远强于人类棋手,而且即使它有bug,人类棋手也几乎找不到。我之前的文章中不断为人类棋手想办法,试图从算法的角度发现AlphaGo的弱点,希望人类棋手能利用其弱点战而胜之。现在看来,由于人类棋手与它差距实在太大,应该放弃这种想法了。
但是人机大战的意义还是很大的,AlphaGo到底有多强大,作为没有自我意识的弱人工智能,它只是一个算术工具,自己肯定不知道。而AlphaGo的开发者Deepmind团队的人类算法大师们,虽然开发出了一个强大到可怕的工具,但自己也难以解读这种强大。人类顶尖棋手通过与AlphaGo的对战,亲自感受到了这种强大,也对AlphaGo作出了高强度的测试。柯洁的第二盘甚至第三盘棋,还是提供了很复杂的局面,AlphaGo都完美地应对了下来。另一方面,AlaphGo不仅是通过战绩让世人震惊,从围棋艺术来说,它的很多招法,都体现了极度的震憾与美感。而这种震憾与美感,是人类的宝贵财富,是艺术精品,只有职业棋手才能最好的阐释,AlphaGo团队反而做不了。所以,人机大战人类棋手与机器并不只是对抗,即使人类失利,双方也共同对围棋艺术作出了极大贡献。
这也是现阶段弱人工智能的意义。人工智能程序越来越强大,但只有人类对手或者使用者,才知道人工智能的意义。更深层的意义,只有等有自主意识的强人工智能来发掘了。从这个角度上看,AlphaGo也让我们对人工智能的哲学意义认识更深。第三局进行的同时,笔者正在观察者网观天下论坛演讲,提前预测柯洁会0:3负,从理性上放弃了战胜AlphaGo的希望。但职业棋手也不是失败,柯洁、李世石以及参与人机大战的所有中国高手,对AI算法意义的阐释,也是很大的贡献。
下面对第三局的关键之处加以解说,并对围棋AI后续的发展作出展望。
一。第三局的关键之处

柯洁白棋开局平稳,至12手是常见局面。AlphaGo的13手是新手。这一手拆一很难想到,但很难应对,白棋容易重复。柯洁在此局部的解决办法是脱先。

柯洁14位尖顶后16位打入,18同样还以一个拆一,并果断出手20位打入角部。这一手也很难应对,黑怎么应都会被利。AlphaGo同样应以脱先。

AlphaGo的21压迫白角部,占住外面。柯洁26手飞出,但AlphaGo仍然执意要控制大势,27位控场,仍然不理右下角。柯洁28手终于忍不住在右下角出手。双方在这几个局部的脱先大战韵味深长。

对柯洁28,AlphaGo简单地29位31位顶住走厚。这个局面白棋花的手数不少,却难以获得重大战果只是单纯破空。可能柯洁28位没忍住有问题。这时柯洁感觉右下角不好走了,再次脱先在右上角32位碰,而AlphaGo作出了令人吃惊的选择,简单地37位占住角,让白38位挡上。但仔细品味,黑右边两子虽然陷入包围,但是仍然很有活力,白并不能将右边算成实空。黑棋39立下威胁白棋左下角和中下的棋,这一手诱发了柯洁的败招。

柯洁40手威胁分断黑棋,是一招严重的问题手,遭到了AlphaGo的反击。AlphaGo不去连接而是41手点角,而白棋却不敢断!如果白切断,由于自身毛病太多,左下角的白棋会被搜刮得很苦,失去了切断的意义。柯洁考虑之后,作出了42冲,44切断黑棋的激烈选择。柯洁的意图是,彻底分断左中五个黑子,把40位威胁切断的意义体现出来。但这是一厢情愿的盘算,事实证明是败招。

柯洁50、54、56将角部紧急处理一下,左下总算是“先手活”。然后58手威胁黑棋,企图让黑棋五子在F5位连回,这种“外边和里边”的交换白便宜了。但是AlphaGo下出了胜招59位罩!这招棋拿住了白棋48这块棋的棋形,白棋怎么应都会变成效率低下的愚型。硬吃黑五子更不可行,没有多少目,外面还会被黑全封住大败。

柯洁被63吃后只好继续脱先做活右下角。这不是好招,而是没办法的脱先。AlphaGo稳稳地71扳73跳。这个结果,白右下角是先手活了。但和左下角的“先手活”一样,目数很少。而且黑外面有借用,几块黑棋都很安全,做眼、出头都方便,还随时可以从71这联络。但白58、70这块棋就很困难,加上60、62这块棋等于是被缠绕攻击。白实空又不足,已经是非常困难的局面了。

柯洁78手补棋的选点很有妙味,是劣势下走得不错的一招。AlphaGo的选择很明快,它简单地走厚右下与右上,放弃了右边两子,让白棋获得了一大块实空。但是黑争得先手89位扳缠绕攻击,柯洁为了下边中间的大块棋安全,只能让黑95长出,左边几个子基本被吃。这个局面,黑棋非常厚实,白棋实空虽然算有,但是大势到处被制,局势已经必败了。但是根源是左下40手和44手的切断,战略上方向大错。

后面柯洁败势下努力拼搏,在中上部形成了一个很复杂的局面。但AlphaGo似乎已经算清了,走出127手静待白棋出招。柯洁苦思良久还是没有办法,上面被吃了,黑棋盘面15目优势,比第一局的优势还大得多。这说明AlphaGo似乎并不惧怕局部的复杂情况,计算能力比其它围棋AI以及之前版本明显提升。包括第二局很复杂的局面,AlphaGo也没有应错,还是能掌控局势的。

这是终局的情况,白中腹大龙无法回家被吃。但这是柯洁拼搏或者说求投场的结果。如果平稳收官大约是盘面十目的劣势,无非是看AlphaGo是不是又送成最小差距。柯洁和昨天的五人一样,选择了壮烈。
本局柯洁发挥不佳,主要的看点还是AlphaGo的妙招,以及双方的几手脱先。柯洁的脱先多半是局部应不好的无奈选择,AlphaGo的脱先有妙味。
二。围棋AI后续将如何发展?人类棋手如何面对?
二次人机大战,AlphaGo以及之前的Master,以令人信服的表现,基本上终结了人类棋手能否战胜它这个悬念。柯洁是对此认识最深的,他赛前就说,这是与AI的最后三盘棋,无论胜负都不下了。因为之后差距会越来越大,与机器对局从胜负上没有意义了。
但这并不是说围棋与人类棋手就会惨遭打击,其实国际象棋早就有这样的事了。国际象棋高手连手机版本都战胜不了,但是国际象棋运动近20年来发展得很好。在AI的帮助下,人类国际象棋水平迅速提升,大师的数量翻了好几倍,正式比赛数量翻了十倍,棋界非常活跃。高等级的比赛很多,人类高手对局时,棋迷们在线观看AI的评棋。AI会实时给出各个选择的后续变化,棋迷们就象监考老师一样盯着双方高手,看他们是下出了好棋还是下出败招,对手是不是找到了惩罚的办法。
相信围棋也会发展成这样,至少从棋迷的角度,观赏比赛不再象以前那样一头雾水。如果真有人类高手像柯洁第二局前50手表现那样,下得和AlphaGo推荐的招数一样,也会得到棋迷与棋手们真心的喝彩。而棋手也会追求这种荣誉,为之兴奋,为之落泪,这种感情是冷冰冰的AlphaGo永远无法体会到的。
近一段时间,棋迷们显得对人类棋手之间对局兴趣下降,对绝艺、AlphaGo与人类高手的对局更有兴趣。我相信这是暂时的,主要原因还是人类棋手水平低犯错太多。如果人类棋手在向AI学棋之后,水平取得巨大进步,有艺术美感的高水平棋局一定会比以前更多,而棋迷们会更有兴趣看人类棋手之间有血性与情感的对局。国际象棋顶级AI之间,动则大战100回合,虽然水平很高,但棋迷们其实看不过来,关注度比卡尔森的世界冠军赛要低得多。
现在顶级的围棋AI只有AlphaGo一个。腾讯绝艺团队的开发似乎进入瓶颈,正如AlphaGo去年的版本,总是会被时间充足的人类对手以一定概率找到Bug。但是这次Deepmind团队已经透露了Master的技术秘密,我上篇文章已经简单介绍了。Deepmind将在6月以论文形式公布更多细节,并将在几个月以后象2016年《自然》那篇文章一样公布非常完整的技术细节。这将对绝艺、DeepZenGo等高水平AI帮助极大,其它开发者也可能迅速追上。
柯洁的意见是,人类的围棋比赛就应该人来下,让AI来是不正确的。国际象棋比赛确实如此,正式比赛不仅AI不能来,还要严查棋手不准AI支招。只有人机结合趣味赛之类的比赛,才让AI来比赛。 接下来6月,梦百合杯64强战就将开打,日本的DeepZenGo特约参赛。如果DeepZenGo连胜两局进入16强,会到9月再续战。这几个月时间,得到Deepmind公布信息的帮助,DeepZenGo的实力很大可能将突飞猛进。即使只是接近Master的水平,DeepZenGo获得最终冠军的可能性也不小。如果柯洁在过程中或者决赛中碰上它,再不与AI对局的宣告也只能放弃了。
当然AI之间互相比赛也是很有意思的,围棋AI肯定也会有很多比赛继续举办。如果其它AI取得实力突破,例如对人类高手也是100%胜率,也可能AlphaGo也会参与“机机大战”。
不管如何,围棋AI的出现对围棋是很好的事,能够促进人类围棋艺术的极大发展。而对“围棋艺术”的理解,又需要职业棋手们的阐释。这从一个侧面,说明了人类与人工智能的辩证关系。
作者: cateyes 时间: 2017-12-13 17:52
标题: Alphago进化史 漫画告诉你Zero为什么这么牛
本帖最后由 cateyes 于 2017-12-13 18:01 编辑
http://sports.sina.com.cn/chess/ ... ymyyxw4023875.shtml
Alphago进化史 漫画告诉你Zero为什么这么牛
2017-10-21 22:18:10 新浪综合
Alphago家族又添新成员
来源:环球科学ScientificAmerican公众号
策划 | 吴非 绘制 | 铁蛋公主



专家评Alphago Zero 成绩令人欣喜但AI还在路上
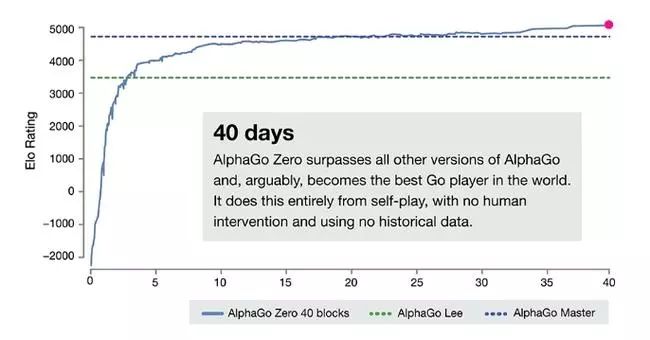
Alphago进步速度示意图
作者:葛熔金
在金庸的小说《射雕英雄传》里,周伯通“左手画圆,右手画方”,左手攻击右手,右手及时反搏,自娱自乐,终无敌于天下。
现实世界中,亦有这么一个“幼童”,他没见过一个棋谱,也没有得到一个人指点,从零开始,自娱自乐,自己参悟,用了仅仅40天,便称霸围棋武林。
这个“幼童”,叫阿尔法元(AlphaGo Zero),就是今年5月在乌镇围棋峰会上打败了人类第一高手柯洁的阿尔法狗强化版AlphaGo Master的同门“师弟”。不过,这个遍读人类几乎所有棋谱、以3比0打败人类第一高手的师兄,在“师弟”阿尔法元从零自学第21天后,便被其击败。
10月19日,一手创造了AlphaGo神话的谷歌DeepMind团队在Nature杂志上发表重磅论文Mastering the game of Go without human knowledge,介绍了团队最新研究成果——阿尔法元的出世,引起业内轰动。
虽师出同门,但是师兄弟的看家本领却有本质的差别。
“过去所有版本的AlphaGo都从利用人类数据进行培训开始,它们被告知人类高手在这个地方怎么下,在另一个地方又怎么下。” DeepMind阿尔法狗项目负责人David Silver博士在一段采访中介绍,“而阿尔法元不使用任何人类数据,完全是自我学习,从自我对弈中实践。”
David Silver博士介绍,在他们所设计的算法中,阿尔法元的对手,或者叫陪练,总是被调成与其水平一致。“所以它是从最基础的水平起步,从零开始,从随机招式开始,但在学习过程中的每一步,它的对手都会正好被校准为匹配器当前水平,一开始,这些对手都非常弱,但是之后渐渐变得越来越强大。”
这种学习方式正是当今人工智能最热门的研究领域之一——强化学习(Reinforcement learning)。
昆山杜克大学和美国杜克大学电子与计算机工程学教授李昕博士向澎湃新闻(
www.thepaper.cn)介绍,DeepMind团队此次所利用的一种新的强化学习方式,是从一个对围棋没有任何知识的神经网络开始,然后与一种强大的搜索算法相结合,“简单地解释就是,它开始不知道该怎么做,就去尝试,尝试之后,看到了结果,若是正面结果,就知道做对了,反之,就知道做错了,这就是它自我学习的方法。”
这一过程中,阿尔法元成为自己的“老师”,神经网络不断被调整更新,以评估预测下一个落子位置以及输赢,更新后的神经网络又与搜索算法重新组合,进而创建一个新的、更强大的版本,然而再次重复这个过程,系统性能经过每一次迭代得到提高,使得神经网络预测越来越准确,阿尔法元也越来越强大。
其中值得一提的是,以前版本的阿尔法狗通常使用预测下一步的“策略网络(policy network)”和评估棋局输赢的“价值网络(value network)”两个神经网络。而更为强大的阿尔法元只使用了一个神经网络,也就是两个网络的整合版本。
这个意义上而言,“AlphaGo Zero”译成“阿尔法元”,而不是字面上的“阿尔法零”,“内涵更加丰富,代表了人类认知的起点——神经元。”李昕教授说。
上述研究更新了人们对于机器学习的认知。“人们一般认为,机器学习就是关于大数据和海量计算,但是通过阿尔法元,我们发现,其实算法比所谓计算或数据可用性更重要。”DavidSilver博士说。
李昕教授长期专注于制造业大数据研究,他认为,这个研究最有意义的一点在于,证明了人工智能在某些领域,也许可以摆脱对人类经验和辅助的依赖。“人工智能的一大难点就是,需要大量人力对数据样本进行标注,而阿尔法元则证明,人工智能可以通过‘无监督数据(unsupervised data)’,也就是人类未标注的数据,来解决问题。”
有人畅想,类似的深度强化学习算法,或许能更容易地被广泛应用到其他人类缺乏了解或是缺乏大量标注数据的领域。
不过,究竟有多大实际意义,能应用到哪些现实领域,李昕教授表示“还前途未卜”,“下围棋本身是一个比较局限的应用,人类觉得下围棋很复杂,但是对于机器来说并不难。而且,下围棋只是一种娱乐方式,不算作人们在生活中遇到的实际问题。”
那么,谷歌的AI为什么会选择围棋?
据《第一财经》报道,历史上,电脑最早掌握的第一款经典游戏是井字游戏,这是1952年一位博士在读生的研究项目;随后是1994年电脑程序Chinook成功挑战西洋跳棋游戏;3年后,IBM深蓝超级计算机在国际象棋比赛中战胜世界冠军加里•卡斯帕罗夫。
除了棋盘游戏外,IBM的Watson系统在2011年成功挑战老牌智力竞赛节目Jeopardy游戏一战成名;2014年,Google自己编写的算法,学会了仅需输入初始像素信息就能玩几十种Atari游戏。
但有一项游戏仍然是人类代表着顶尖水平,那就是围棋。
谷歌DeepMind创始人兼CEO Demis Hassabis博士曾在2016年AlphaGo对阵李世石时就做过说明,有着3000多年历史的围棋是人类有史以来发明出来的最复杂的游戏,对于人工智能来说,这是一次最尖端的大挑战,需要直觉和计算,要想熟练玩围棋需要将模式识别和运筹帷幄结合。
“围棋的搜索空间是漫无边际的——比围棋棋盘要大1个古戈尔(数量级单位,10的100次方,甚至比宇宙中的原子数量还要多)。”因此,传统的人工智能方法也就是“为所有可能的步数建立搜索树”,在围棋游戏中几乎无法实现。
而打败了人类的AlphaGo系统的关键则是,将围棋巨大无比的搜索空间压缩到可控的范围之内。David Silver博士此前曾介绍,策略网络的作用是预测下一步,并用来将搜索范围缩小至最有可能的那些步骤。另一个神经网络“价值网络(valuenetwork)”则是用来减少搜索树的深度,每走一步估算一次游戏的赢家,而不是搜索所有结束棋局的途径。
李昕教授对阿尔法元带来的突破表示欣喜,但同时他也提到,“阿尔法元证明的只是在下围棋这个游戏中,无监督学习(unsupervised learning)比有监督学习(supervised learning)‘更优’,但并未证明这就是‘最优’方法,也许两者结合的semi-supervised learning,也就是在不同时间和阶段,结合有监督或无监督学习各自的优点,可以得到更优的结果。”
李昕教授说,人工智能的技术还远没有达到人们所想象的程度,“比如,互联网登录时用的reCAPTCHA验证码(图像或者文字),就无法通过机器学习算法自动识别”,他说,在某些方面,机器人确实比人做得更好,但目前并不能完全替换人。“只有当科研证明,一项人工智能技术能够解决一些实际问题和人工痛点时,才真正算作是一个重大突破。”
昆山杜克大学常务副校长、中美科技政策和关系专家丹尼斯·西蒙(Denis Simon)博士在接受澎湃新闻采访时表示,阿尔法元在围棋领域的成功说明它确实有极大的潜力。阿尔法元通过与自身对弈实现了自身能力的提升,每一次它都变得更聪明,每一次棋局也更有挑战性。这种重复性的、充分参与的学习增强了阿尔法元处理更高层次的、战略复杂问题的能力。但缺点是这是一个封闭的系统。“阿尔法元如何能够超过自身的局限获得进一步的成长?换句话说,它能跳出框框思考吗?”
AI科学家详解AlphaGo Zero的伟大与局限

AlphaGo Zero
(文章来源:量子位 报道 | 公众号 QbitAI 作者:夏乙 李根 发自 凹非寺 )
“人类太多余了。”
面对无师自通碾压一切前辈的AlphaGo Zero,柯洁说出了这样一句话。
如果你无法理解柯洁的绝望,请先跟着量子位回顾上一集:
今年5月,20岁生日还未到的世界围棋第一人柯洁,在乌镇0:3败给了DeepMind的人工智能程序AlphaGo,当时的版本叫做Master,就是今年年初在网上60:0挑落中日韩高手的那个神秘AI。
AlphaGo Zero骤然出现,可以说是在柯洁快要被人类对手和迷妹们治愈的伤口上,撒了一大把胡椒粉。
被震动的不止柯洁,在DeepMind的Nature论文公布之后,悲观、甚至恐慌的情绪,在大众之间蔓延着,甚至有媒体一本正经地探讨“未来是终结者还是黑客帝国”。
于是,不少认真读了论文的人工智能“圈内人”纷纷站出来,为这次技术进展“去魅”。
无师自通?
首当其冲的问题就是:在AlphaGo Zero下棋的过程中,人类知识和经验真的一点用都没有吗?
在这一版本的AlphaGo中,虽说人类的知识和经验没多大作用,但也不至于“多余”。
在Zero下棋的过程中,并没有从人类的对局经验和数据中进行学习,但这个算法依然需要人类向它灌输围棋的规则:哪些地方可以落子、怎样才算获胜等等。
剩下的,就由AI自己来搞定了。
对于这个话题,鲜有人比旷视科技首席科学家孙剑更有发言权了,因为AlphaGo Zero里面最核心使用的技术ResNet,正是孙剑在微软亚洲研究院时期的发明。

孙剑
孙剑也在接受量子位等媒体采访的过程中,对AlphaGo Zero的“无师自通”作出了评价,他认为这个说法“对,也不对”,并且表示“伟大与局限并存”。
究竟对不对,还是取决于怎样定义无师自通,从哪个角度来看。
和之前三版AlphaGo相比,这一版去掉了人类教授棋谱的过程,在训练过程最开始的时候,AI落子完全是随机的,AlphaGo团队的负责人David Silver透露,它一开始甚至会把开局第一手下在1-1。在和自己对弈的过程中,算法才逐渐掌握了胜利的秘诀。
从这个角度来看,Zero的确可以说是第一次做到了无师自通,也正是出于这个原因,DeepMind这篇Nature论文才能引起这么多圈内人关注。
但要说它是“无监督学习”,就有点“不对”。孙剑说:“如果仔细看这个系统,它还是有监督的。”它的监督不是来自棋谱,而是围棋规则所决定的最后谁输谁赢这个信号。
“从这个意义上说,它不是百分之百绝对的无师自通,而是通过这个规则所带来的监督信号,它是一种非常弱监督的增强学习,它不是完全的无师自通。”
孙剑还进一步强调:“但是同时这种无师自通在很多AI落地上也存在一些局限,因为严格意义上讲,围棋规则和判定棋局输赢也是一种监督信号,所以有人说人类无用、或者说机器可以自己产生认知,都是对AlphaGo Zero错误理解。”
离全面碾压人类有多远?

Zero发布之后,媒体关切地询问“这个算法以后会用在哪些其他领域”,网友认真地担心“这个AI会不会在各个领域全面碾压人类”。
对于Zero算法的未来发展,DeepMind联合创始人哈萨比斯介绍说,AlphaGo团队的成员都已经转移到其他团队中,正在尝试将这项技术用到其他领域,“最终,我们想用这样的算法突破,来解决真实世界中各种各样紧迫的问题。”
DeepMind期待Zero解决的,是“其他结构性问题”,他们在博客中特别列举出几项:蛋白质折叠、降低能耗、寻找革命性的新材料。
哈萨比斯说AlphaGo可以看做一个在复杂数据中进行搜索的机器,除了博客中提到几项,新药发现、量子化学、粒子物理学也是AlphaGo可能大展拳脚的领域。
不过,究竟哪些领域可以扩展、哪些领域不行呢?
孙剑说要解释AlphaGo算法能扩展到哪些领域,需要先了解它现在所解决的问题——围棋——具有哪些特性。
首先,它没有噪声,是能够完美重现的算法;
其次,围棋中的信息是完全可观测的,不像在麻将、扑克里,对手的信息观测不到;
最后也是最重要的一点,是围棋对局可以用计算机迅速模拟,很快地输出输赢信号。
基于对围棋这个领域特性的理解,提到用AlphaGo算法来发现新药,孙剑是持怀疑态度的。
他说,发现新药和下围棋之间有一个非常显著的区别,就是“输赢信号”能不能很快输出:“新药品很多内部的结构需要通过搜索,搜索完以后制成药,再到真正怎么去检验这个药有效,这个闭环非常代价昂贵,非常慢,你很难像下围棋这么简单做出来。”
不过,如果找到快速验证新药是否有效的方法,这项技术就能很好地用在新药开发上了。
而用AlphaGo算法用来帮数据中心节能,孙剑就认为非常说得通,因为它和围棋的特性很一致,能快速输出结果反馈,也就是AlphaGo算法依赖的弱监督信号。
当然,从AlphaGo算法的这些限制,我们也不难推想,它在某些小领域内可以做得非常好,但其实并没有“全面碾压人类”的潜力。
去魅归去魅,对于AlphaGo Zero的算法,科研人员纷纷赞不绝口。
大道至简的算法
在评价Zero的算法时,创新工场AI工程院副院长王咏刚用了“大道至简”四个字。
简单,是不少人工智能“圈内人”读完论文后对Zero的评价。刚刚宣布将要跳槽伯克利的前微软亚洲研究院首席研究员马毅教授就发微博评论说,这篇论文“没有提出任何新的方法和模型”,但是彻底地实现了一个简单有效的想法。

为什么“简单”这件事如此被学术圈津津乐道?孙剑的解释是“我们做研究追求极简,去除复杂”,而Zero的算法基本就是在前代基础上从各方面去简化。
他说,这种简化,一方面体现在把原来的策略网络和价值网络合并成一个网络,简化了搜索过程;另一方面体现在用深度残差网络(ResNet)来对输入进行简化,以前需要人工设计棋盘的输入,体现“这个子下过几次、周围有几个黑子几个白子”这样的信息,而现在是“把黑白子二值的图直接送进来,相当于可以理解成对着棋盘拍照片,把照片送给神经网络,让神经网络看着棋盘照片做决策”。
孙剑认为,拟合搜索和ResNet,正是Zero算法中的两个核心技术。
其中拟合搜索所解决的问题,主要是定制化,它可以对棋盘上的每一次落子都进行量化,比如会对最终获胜几率做多大贡献,但是这其实并不是近期才产生的一种理论,而是在很早之前就存在的一种基础算法理论。
而另一核心技术是最深可达80层的ResNet。总的来说,神经网络越深,函数映射能力就越强、越有效率,越有可能有效预测一个复杂的映射。
下围棋时要用到的,就是一个非常复杂的映射,神经网络需要输出每个可能位置落子时赢的概率,也就是最高要输出一个361维的向量。这是一个非常复杂的输出,需要很深的网络来解决。
人类棋手下棋,落子很多时候靠直觉,而这背后实际上有一个非常复杂的函数,Zero就用深层ResNet,拟合出了这样的函数。
ResNet特点就是利用残差学习,让非常深的网络可以很好地学习,2015年,孙剑带领的团队就用ResNet把深度神经网络的层数从十几二十层,推到了152层。
也正是凭借这样的创新,孙剑团队拿下了ImageNet和MSCOCO图像识别大赛各项目的冠军。到2016年,他们又推出了第一个上千层的网络,获得了CVPR最佳论文奖。
而令孙剑更加意料之外的是,ResNet还被AlphaGo团队看中,成为AlphaGo Zero算法中的核心组件之一。
这位Face++首席科学家表示很开心为推动整个AI进步“做了一点微小的贡献”,同时也很钦佩DeepMind团队追求极致的精神。
任剑还说,在旷视研究院的工作中,还会不断分享、开放研究成果,更注重技术在产业中的实用性,进一步推动整个AI产业的进步。
另外,还有不少AI大咖和知名科研、棋手对AlphaGo Zero发表了评价,量子位汇集如下:
大咖评说AlphaGo Zero
李开复:AI进化超人类想象,但与“奇点”无关
昨天AlphaGo Zero横空出世,碾压围棋界。AlphaGo Zero完全不用人类过去的棋谱和知识,就再次打破人类认知。很多媒体问我对AlphaGo Zero的看法,我的观点是:一是AI前进的速度比想象中更快,即便是行业内的人士都被AlphaGo Zero跌破眼镜;二是要正视中国在人工智能学术方面和英美的差距。
一方面,AlphaGo Zero的自主学习带来的技术革新并非适用于所有人工智能领域。围棋是一种对弈游戏,是信息透明,有明确结构,而且可用规则穷举的。对弈之外,AlphaGo Zero的技术可能在其他领域应用,比如新材料开发,新药的化学结构探索等,但这也需要时间验证。而且语音识别、图像识别、自然语音理解、无人驾驶等领域,数据是无法穷举,也很难完全无中生有。AlphaGo Zero的技术可以降低数据需求(比如说WayMo的数据模拟),但是依然需要大量的数据。
另一方面,AlphaGo Zero里面并没有新的巨大的理论突破。它使用的Tabula Rosa learning(白板学习,不用人类知识),是以前的围棋系统Crazy Stone最先使用的。AlphaGo Zero里面最核心使用的技术ResNet,是微软亚洲研究院的孙剑发明的。孙剑现任旷视科技Face++首席科学家。
虽然如此,这篇论文的影响力也是巨大的。AlphaGo Zero 能够完美集成这些技术,本身就具有里程碑意义。DeepMind的这一成果具有指向标意义,证明这个方向的可行性。在科研工程领域,探索前所未知的方向是困难重重的,一旦有了可行性证明,跟随者的风险就会巨幅下降。我相信从昨天开始,所有做围棋对弈的研究人员都在开始学习或复制AlphaGo Zero。材料、医疗领域的很多研究员也开始探索。
AlphaGo Zero的工程和算法确实非常厉害。但千万不要对此产生误解,认为人工智能是万能的,所有人工智能都可以无需人类经验从零学习,得出人工智能威胁论。AlphaGo Zero证明了AI 在快速发展,也验证了英美的科研能力,让我们看到在有些领域可以不用人类知识、人类数据、人类引导就做出顶级的突破。但是,AlphaGo Zero只能在单一简单领域应用,更不具有自主思考、设定目标、创意、自我意识。即便聪明如AlphaGo Zero,也是在人类给下目标,做好数字优化而已。这项结果并没有推进所谓“奇点”理论。
南大周志华:与“无监督学习”无关
花半小时看了下文章,说点个人浅见,未必正确仅供批评:
别幻想什么无监督学习,监督信息来自精准规则,非常强的监督信息。
不再把围棋当作从数据中学习的问题,回归到启发式搜索这个传统棋类解决思路。这里机器学习实质在解决搜索树启发式评分函数问题。
如果说深度学习能在模式识别应用中取代人工设计特征,那么这里显示出强化学习能在启发式搜索中取代人工设计评分函数。这个意义重大。启发式搜索这个人工智能传统领域可能因此巨变,或许不亚于模式识别计算机视觉领域因深度学习而产生的巨变。机器学习进一步蚕食其他人工智能技术领域。
类似想法以往有,但常见于小规模问题。没想到围棋这种状态空间巨大的问题其假设空间竟有强烈的结构,存在统一适用于任意多子局面的评价函数。巨大的状态空间诱使我们自然放弃此等假设,所以这个尝试相当大胆。
工程实现能力超级强,别人即便跳出盲点,以启发式搜索界的工程能力也多半做不出来。
目前并非普适,只适用于状态空间探索几乎零成本且探索过程不影响假设空间的任务。
Facebook田渊栋:AI穷尽围棋还早
老实说这篇Nature要比上一篇好很多,方法非常干净标准,结果非常好,以后肯定是经典文章了。
Policy network和value network放在一起共享参数不是什么新鲜事了,基本上现在的强化学习算法都这样做了,包括我们这边拿了去年第一名的Doom Bot,还有ELF里面为了训练微缩版星际而使用的网络设计。另外我记得之前他们已经反复提到用Value network对局面进行估值会更加稳定,所以最后用完全不用人工设计的defaultpolicy rollout也在情理之中。
让我非常吃惊的是仅仅用了四百九十万的自我对局,每步仅用1600的MCTS rollout,Zero就超过了去年三月份的水平。并且这些自我对局里有很大一部分是完全瞎走的。这个数字相当有意思。想一想围棋所有合法状态的数量级是10^170(见Counting Legal Positions in Go),五百万局棋所能覆盖的状态数目也就是10^9这个数量级,这两个数之间的比例比宇宙中所有原子的总数还要多得多。仅仅用这些样本就能学得非常好,只能说明卷积神经网络(CNN)的结构非常顺应围棋的走法,说句形象的话,这就相当于看了大英百科全书的第一个字母就能猜出其所有的内容。用ML的语言来说,CNN的inductivebias(模型的适用范围)极其适合围棋漂亮精致的规则,所以稍微给点样本水平就上去了。反观人类棋谱有很多不自然的地方,CNN学得反而不快了。我们经常看见跑KGS或者GoGoD的时候,最后一两个百分点费老大的劲,也许最后那点时间完全是花费在过拟合奇怪的招法上。
如果这个推理是对的话,那么就有几点推断。一是对这个结果不能过分乐观。我们假设换一个问题(比如说protein folding),神经网络不能很好拟合它而只能采用死记硬背的方法,那泛化能力就很弱,Self-play就不会有效果。事实上这也正是以前围棋即使用Self-play都没有太大进展的原因,大家用手调特征加上线性分类器,模型不对路,就学不到太好的东西。一句话,重点不在左右互搏,重点在模型对路。
二是或许卷积神经网络(CNN)系列算法在围棋上的成功,不是因为它达到了围棋之神的水平,而是因为人类棋手也是用CNN的方式去学棋去下棋,于是在同样的道路上,或者说同样的inductive bias下,计算机跑得比人类全体都快得多。假设有某种外星生物用RNN的方式学棋,换一种inductive bias,那它可能找到另一种(可能更强的)下棋方式。Zero用CNN及ResNet的框架在自学习过程中和人类世界中围棋的演化有大量的相似点,在侧面上印证了这个思路。在这点上来说,说穷尽了围棋肯定是还早。
三就是更证明了在理论上理解深度学习算法的重要性。对于人类直觉能触及到的问题,机器通过采用有相同或者相似的inductive bias结构的模型,可以去解决。但是人不知道它是如何做到的,所以除了反复尝试之外,人并不知道如何针对新问题的关键特性去改进它。如果能在理论上定量地理解深度学习在不同的数据分布上如何工作,那么我相信到那时我们回头看来,针对什么问题,什么数据,用什么结构的模型会是很容易的事情。我坚信数据的结构是解开深度学习神奇效果的钥匙。
另外推测一下为什么要用MCTS而不用强化学习的其它方法(我不是DM的人,所以肯定只能推测了)。MCTS其实是在线规划(online planning)的一种,从当前局面出发,以非参数方式估计局部Q函数,然后用局部Q函数估计去决定下一次rollout要怎么走。既然是规划,MCTS的限制就是得要知道环境的全部信息,及有完美的前向模型(forward model),这样才能知道走完一步后是什么状态。围棋因为规则固定,状态清晰,有完美快速的前向模型,所以MCTS是个好的选择。但要是用在Atari上的话,就得要在训练算法中内置一个Atari模拟器,或者去学习一个前向模型(forward model),相比actor-critic或者policy gradient可以用当前状态路径就地取材,要麻烦得多。但如果能放进去那一定是好的,像Atari这样的游戏,要是大家用MCTS我觉得可能不用学policy直接当场planning就会有很好的效果。很多文章都没比,因为比了就不好玩了。
另外,这篇文章看起来实现的难度和所需要的计算资源都比上一篇少很多,我相信过不了多久就会有人重复出来,到时候应该会有更多的insight。大家期待一下吧。
清华大学马少平教授:不能认为AI数据问题解决了
从早上开始,就被AlphaGo Zero的消息刷屏了,DeepMind公司最新的论文显示,最新版本的AlphaGo,完全抛弃了人类棋谱,实现了从零开始学习。
对于棋类问题来说,在蒙特卡洛树搜索的框架下,实现从零开始学习,我一直认为是可行的,也多次与别人讨论这个问题,当今年初Master推出时,就曾预测这个新系统可能实现了从零开始学习,可惜根据DeepMind后来透露的消息,Master并没有完全抛弃人类棋谱,而是在以前系统的基础上,通过强化学习提高系统的水平,虽然人类棋谱的作用越来越弱,但是启动还是学习了人类棋谱,并没有实现“冷”启动。
根据DeepMind透露的消息,AlphaGo Zero不但抛弃了人类棋谱,实现了从零开始学习,连以前使用的人类设计的特征也抛弃了,直接用棋盘上的黑白棋作为输入,可以说是把人类抛弃的彻彻底底,除了围棋规则外,不使用人类的任何数据和知识了。仅通过3天训练,就可以战胜和李世石下棋时的AlphaGo,而经过40天的训练后,则可以打败与柯洁下棋时的AlphaGo了。
真是佩服DeepMind的这种“把革命进行到底”的作风,可以说是把计算机围棋做到了极致。
那么AlphaGo Zero与AlphaGo(用AlphaGo表示以前的版本)都有哪些主要的差别呢?
1。在训练中不再依靠人类棋谱。AlphaGo在训练中,先用人类棋谱进行训练,然后再通过自我互博的方法自我提高。而AlphaGo Zero直接就采用自我互博的方式进行学习,在蒙特卡洛树搜索的框架下,一点点提高自己的水平。
2。不再使用人工设计的特征作为输入。在AlphaGo中,输入的是经过人工设计的特征,每个落子位置,根据该点及其周围的棋的类型(黑棋、白棋、空白等)组成不同的输入模式。而AlphaGo Zero则直接把棋盘上的黑白棋作为输入。这一点得益于后边介绍的神经网络结构的变化,使得神经网络层数更深,提取特征的能力更强。
3。将策略网络和价值网络合二为一。在AlphaGo中,使用的策略网络和价值网络是分开训练的,但是两个网络的大部分结构是一样的,只是输出不同。在AlphaGo Zero中将这两个网络合并为一个,从输入到中间几层是共用的,只是后边几层到输出层是分开的。并在损失函数中同时考虑了策略和价值两个部分。这样训练起来应该 会更快吧?
4。网络结构采用残差网络,网络深度更深。AlphaGo Zero在特征提取层采用了多个残差模块,每个模块包含2个卷积层,比之前用了12个卷积层的AlphaGo深度明显增加,从而可以实现更好的特征提取。
5。不再使用随机模拟。在AlphaGo中,在蒙特卡洛树搜索的过程中,要采用随机模拟的方法计算棋局的胜率,而在AlphaGo Zero中不再使用随机模拟的方法,完全依靠神经网络的结果代替随机模拟。这应该完全得益于价值网络估值的准确性,也有效加快了搜索速度。
6。只用了4块TPU训练72小时就可以战胜与李世石交手的AlphaGo。训练40天后可以战胜与柯洁交手的AlphaGo。
对于计算机围棋来说,以上改进无疑是个重要的突破,但也要正确认识这些突破。比如,之所以可以实现从零开始学习,是因为棋类问题的特点所决定的,是个水到渠成的结果。因为棋类问题一个重要的特性就是可以让机器自动判别最终结果的胜负,这样才可以不用人类数据,自己实现产生数据,自我训练,自我提高下棋水平。但是这种方式很难推广到其他领域,不能认为人工智能的数据问题就解决了。
对于计算机围棋来说,以上改进无疑是个重要的突破,但也要正确认识这些突破。比如,之所以可以实现从零开始学习,是因为棋类问题的特点所决定的,是个水到渠成的结果。因为棋类问题一个重要的特性就是可以让机器自动判别最终结果的胜负,这样才可以不用人类数据,自己实现产生数据,自我训练,自我提高下棋水平。但是这种方式很难推广到其他领域,不能认为人工智能的数据问题就解决了。
Rokid祝铭明:数据学习到评分方法学习的切换
Alpha Zero的文章有多少人认真看过,就在传无监督学习,这次有意思的是方法其实有点回归传统规则指导的思考模式。如果这个算是无监督学习,那几十年前就有了。只是这次是超大空间下的基于规则的决策树裁决评分,文章最有价值的是把之前数据学习变成了评分方法学习,这个其实有点意思,对于规则清晰问题可以大大减少数据依赖。
简单说这个就是如何通过学习,避免对超大规模搜索树的遍历,同时保证决策打分的合理性。其实有点白盒子的味道。这方法的确在很多规则简单清晰,但空间规模大的问题上有启发意义,而且从理论上来说肯定比之前的基于数据学习的要优秀很多,因为过去的方法仍然对经验数据依赖。不过和大家说的无监督学习是两码事。这么说大家都能理解了吧。
即将加入加州伯克利的马毅教授
熬夜读完AlphaGo zero的Nature论文,深有感触:我们一生与多少简单而又有效的想法失之交臂,是因为我们或者过早认为这些想法不值得去做或者没有能力或毅力正确而彻底地实现它们?这篇论文可以说没有提出任何新的方法和模型——方法可以说比以前的更简单“粗暴”。但是认真正确彻底的验证了这个看似简单的想法到底work不work。在做研究上,这往往才是拉开人与人之间差距的关键。
柯洁九段
一个纯净、纯粹自我学习的AlphaGo是最强的…对于AlphaGo的自我进步来讲…人类太多余了。
还有一些零散讨论:
微软全球资深副总裁、美国计算机协会(ACM)院士Peter Lee认为这是一个激动人心的成果,如果应用到其他领域会有很多前景。其中的理论与康奈尔大学计算机系教授、1986年图灵奖获得者John Hopcroft之前下国际象棋的工作相似,而且Deepmind之前做的德州扑克比围棋搜索空间更大、更难。不过受限规则下的围棋跟现实世界的应用场景有天壤之别,现在的自动驾驶、商业决策比游戏复杂很多。
John Hopcroft提到了他常说的监督学习和非监督学习,因为给大量数据标标签是一件非常难的事情。他还说,现在AI还在工程阶段,我们先是把飞机飞向天,此后才理解了空气动力学。AI现在能告诉你是谁,未来能告诉你在想什么,再之后会有理论解释为什么这能工作。
美国人工智能学会(AAAI)院士Lise Getoor认为,在监督学习和非监督学习之上还有结构化学习,如何让机器发现可能是递归的ontological commitment。我们现在的深度学习模型可能存在structure bias。
杨强教授没有说话,不过AlphaGo Zero论文刚一发布,他担任理事会主席的国际人工智能大会(IJCAI)就为这支团队颁发了第一枚马文·明斯基奖章,可谓最高赞许。
AlphaGo从零开始自学围棋为什么能成功
不要片面强调说人类知识没用,还不如零知识。Master与AlphaGo Zero从算法层面看,差距很小。
陈经
2017年10月19日
(本文原发于观察者网:AlphaGo从零开始自学围棋为什么能成功)
一。AlphaGo从零开始自学习新版本算法框架与等级分表现
2017年10月18日,业界非常期待的AlphagGo新论文终于在《自然》上发表了。Deepmind开发了一个名为AlphaGo Zero的新版本,它只用一个策略与价值合体的神经网络下棋,从随机走子开始自我对弈学习,完全不需要人类棋谱。新的强化学习策略极为高效,只用3天,AlphaGo Zero就以100:0完全击败了2016年3月轰动世界的AlphaGo Lee。经过21天的学习,它达到了Master的实力(而Master在2017年5月3:0胜人类第一柯洁)。
40天后,它能以90%的胜率战胜Master,成为目前最强的围棋程序。而且AlphaGo Zero的计算过程中直接由神经网络给出叶子节点胜率,不需要快速走子至终局,计算资源大大节省,只需要4个TPU就行(AlphaGo Lee要48个)。
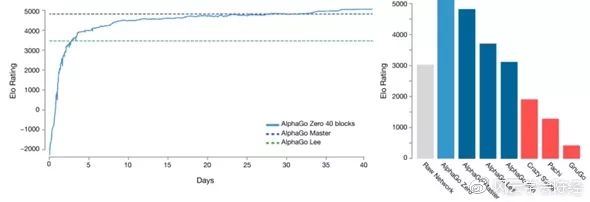
从Goratings棋力等级分上看,AlphaGo Zero其实和Master还能比较,只多个300多分。这相当于论文发表当天,人类第一柯洁九段的3667分与第38名的人气主播孟泰龄六段3425分的分差,两人肯定实力有差距,但也还有得下。论文公布了AlphaGo Zero的83局棋谱,其中与Master下的有20局,Master在第11局还胜了一局。
AlphaGo新版本从零开始训练成功,这个结果大大出乎了我的预料,相信也让业界不少人感到震惊。我本来是预期看到Master的算法解密,为什么它能碾压人类高手。AlphaGo退役让人以为Deepmind不研究围棋了,剩下任务是把Master版本的算法细节在《自然》公布出来,腾讯的绝艺等AI就可以找到开发方向突破目前的实力瓶颈了。
本来5月的乌镇围棋大会上说,6月新论文就能出来了,开发者们可以参考了。至于从零知识开始学习,是个有趣的想法,2016年3月人机大战胜李世石后就有这样的风声,人们期待这个“山洞中左右互搏”的版本出来,与人类的下法是不是很不相同,如开局是不是会占天元?但是后来一直好像没进展,乌镇也没有提。
好几个月了,新论文一直没出来。绝艺明显进入发展瓶颈,总是偶而会输给人,还输给了DeepZenGo与CGI。各个借鉴AlphaGo的AI都迫切需要Deepmind介绍新的思路与细节。到8月跑出来一篇AlphaGo打星际争霸的论文,从零知识开始学,学人类录像打,两种办法都不太行。
这时我认为让AlphaGo从零知识开始学可能不太成功,会陷入局部陷阱,人类棋谱能提供一个“高起点”,高水平AI还是需要人类的“第一推动”。
实际是Deepmind团队认为,仅仅写Master对于《自然》级别的文章不够震憾。新的论文标题是 “Mastering the Game of Go without Human Knowledge”,这个主题升华就足够了。而Master用人类棋谱训练了初始的策略网络,人类知识还是有影响,虽然后来自学习提升后人类影响很小了。对于不懂围棋或者对算法细节不关心的人,Master相比AlphaGo Lee无非是棋力更强一些,战胜的柯洁与李世石都是顶级高手没本质区别,Master的创新性也需要懂围棋才能明白。
AlphaGo Zero是真正的从零开始训练,整个学习过程与人类完全没有关系,全是自己学,这个哲学意义还是很大的。过程中与人或者其它版本下,只是验证棋力不是学招。
二。真正的算法突破是Master版本实现的
可以认为,在技术上从AlphaGo Lee进步到Master是比较难的,需要真正的变革,神经网络架构需要大变,强化学习过程也要取得突破。绝艺、DeepZenGo等AI开发就一直卡在这个阶段,突破不了AlphaGo Lee的水平,总是出bug偶尔输给人,离Master差距很大。
但如果Master的开发成功了,再去试AlphaGo Zero就是顺理成章的事。如果它能训练成功,应该是比较快的事,实际不到半年顶级论文就出来了,回头看是个自然的进展。Deepmind团队在五月后应该是看到了成功的希望,于是继续开发出了AlphaGo Zero,新论文虽然推迟了,但再次震惊了业界。
也可以看出,2016年Deepmind《自然》论文描述的强化学习过程,整个训练流水线比较复杂,要训练好几种神经网络的系数,进化出一个新版本需要几个星期。用这个训练流水线,从零开始强化学习,应该是意义不大,所以一直没有进展。
但是Master的自学习过程取得了重大突破,之前从人类棋谱开始训练2个月的水平,改进后只要一星期就行了,学习效率,以及能够达到的实力上限都有了很大进展。以此为基础,再把从零开始引进来,就能取得重大突破。所以Deepmind真正的技术突破,应该是开发Master时取得的。AlphaGo Zero是Master技术成果的延续,但看上去哲学与社会意义更重大。
Master与AlphaGo Zero的成功,是机器强化学习算法取得巨大发展的成果与证明。训练需要的局数少了,490万局就实现了AlphaGo Lee的水平。而绝艺到2017年3月就已经自我对弈了30亿局,实力一直卡着没有重大进步,主要应该是强化学习技术上有差距。
我在2017年1月9日写的《AlphaGo升级成Master后的算法框架分析》文中进行了猜测:
从实战表现反推,Master的价值网络质量肯定已经突破了临界点,带来了极大的好处,思考时间大幅减少,搜索深度广度增加,战斗力上升。AlphaGo团队新的prototype,架构上可能更简单了,需要的CPU数目也减少了,更接近国际象棋的搜索框架,而不是以MCTS为基础的复杂框架。比起国际象棋AI复杂的人工精心编写的局面评估函数,AlphaGo的价值网络完全由机器学习生成,编码任务更为简单。
理论上来说,如果价值网络的估值足够精确,可以将叶子节点价值网络的权重上升为1.0,就等于在搜索框架中完全去除了MCTS模块,和传统搜索算法完全一样了。这时的围棋AI将从理论上完全战胜人,因为人能做的机器都能做,而且还做得更好更快。而围棋AI的发展过程可以简略为两个阶段。第一阶段局面估值函数能力极弱,被逼引入MCTS以及它的天生弱点。第二阶段价值网络取得突破,再次将MCTS从搜索框架逐渐去除返朴归真,回归传统搜索算法。
从新论文的介绍来看, 这个猜测完全得到了证实。Master和AlphaGo Zero的架构确实更简单了,只需要4个TPU。AlphaGo Zero到叶子节点就完全不用rollout下完数子了,直接用价值网络(已经与策略网络合并)给出胜率,就等于是“价值网络的权重上升为1.0”。Master有没有rollout没有明确说,从实战表现看应该是取消了。
当然新论文中还是将搜索框架称为“MCTS”,因为有随机试各分支,但这不是新东西,和传统搜索差异不算大。对围棋来说,2006年引入MCTS算法真正的独特之处是从叶子节点走完数子,代替难以实现的评估函数。
这种疯狂的海量终局模拟更像是绝望之下的权宜之计,也把机器弄得很疲惫。但是Master与AlphaGo Zero都成功训练出了极为犀利的价值网络,从而又再次将rollout取消。价值网络的高效剪枝,让Master与AlphaGo Zero的判断极为精确,从而算得更为深远战斗力极为强大。这个价值网络怎么训练出来,就是现在Deepmind的独门绝技。可以说,新论文最有价值的就是这个部分。
从Master开始,AlphaGo的网络结构应该就有大变了。到AlphaGo Zero,将价值与策略网络合为一个,这并不奇怪。因为第一篇论文中,就明确说价值与策略网络的架构是完全一样的,只是系数不同。那么二者共用一个网络也不奇怪,前面盘面特征表述应该是一样的,等需要不同的输出时再分出不同的系数。Master网络结构大变之后,也许Deepmind发现,许多盘面特征都可以训练出来,所以就简单将盘面输入简化成黑白。
AlphaGo Zero的强化学习过程,应该与Master差不多,都是成功地跳出了陷阱,不断提升到超乎人类想象的程度。Master从研发上来说,像一个探路先锋,证明了这条路是可以跑通的,能把等级分增加1000分。而AlphaGo Zero,像是一个更为精减的过程,本质是与Master类似的。
新论文中的AlphaGo Zero确实显得架构优美。只需要一个网络,既告诉机器可以下哪,也能给出局面的胜率。盘面输入就是黑白,也不需要任何人类知识。强化学习就是两招,搜索的结果好于神经网络直觉想下的点,可以用于策略选点的训练,一盘下完的结果回头用于修正胜率,都很自然。但是为了实现这个优美结果,需要勇敢的探索。一开始的AlphaGo并没有这么优美,路跑通了,才想到原来可以做得更简单。
本文再提出一个猜测:现在的绝艺、DeepZenGo等AI实力接近AlphaGo Lee了,但都经常出现死活bug,会怎么出和人类对手的实力关系不大,并不是对手等级分高的它就容易出bug,基本是自己莫明其妙送死。这个bug的原因是rollout模块带来的,因为rollout策略是人类棋谱训练出来的,也可能有人工加代码打补丁。
它的目的是快速下完终局,但如果牵涉到死活,这种快速下完就不太可靠了,活的下死,死的杀活。但是,怎么实现不出错的rollout,这非常困难,应该是不可能完成的任务。Master和AlphaGo Zero的办法,是取消这个不可靠的rollout,直接让神经网络给出结果。如果神经网络给出的胜率结果有问题,那就靠训练来解决。这样纠错,强过程序员去排查rollout代码里出了什么错。
三。机器与人类对围棋的适应能力差异很大
Master和AlphaGo Zero的突破说明,在极高的水平上,需要考虑出现瓶颈的原因。人类棋谱能够提供一个“高起点”,但是机器从零开始训练一两天也就追上了,带来的“先发优势”没多少。而人类棋谱中显然有一些“有害成分”,这可能将AI的学习过程带歪。如果AI不能找到消除这些“人类病毒”的办法,那训练就会陷入瓶颈。如下图,零知识强化学习的版本实力迅速追上有人类棋谱帮忙的。
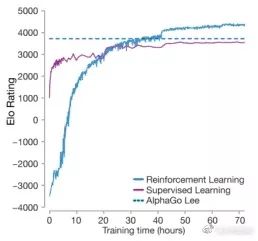
从围棋本身看,它的规则几乎是所有游戏中最优美最简单的。规则就是两句话可以了,气尽提子,禁全同(打劫的由来)。甚至贴目这样的胜负规则都是人类强加的,围棋游戏不需要胜负规则就可以成为一个定义明确的游戏。打砖块这样的Atari游戏就是这样,目标就是打到更高的分。围棋游戏的目标可以是占更多的地,结果可能是黑183、184、185子这样,不需要明确说出黑胜黑负。黑白博弈,会有一个上帝知道的“均衡”结果,猜测可能是黑184子白177子,或者黑184.5白176.5(有眼双活)。
这是一个优美的博弈问题,是掌握了强化学习方法的AI最喜欢的游戏,规则这么简单,太容易了。最终强大的围棋AI,应该是自然的,开发只依靠原始规则,不需要其它的信息了。AlphaGo Zero应该已经接近了这个目标,除了中国规则强加的7.5目的贴目。也许以后可以让AlphaGo不考虑贴目了,黑白都直接优化占地的多少,不再以胜率为目标,说不定能训练出一个更优秀的AI。如优势时不会退让了,劣势时也不自杀。这次Master与AlphaGo Zero一些局终局输定时就表现得很搞笑,有时摇头劫死棋打个没完。
AlphaGo Zero的棋力提升过程非常流畅,说明围棋精致的规则形成的数学空间很优美,神经网络很快就能抓住围棋空间的特征,表现得非常适应。而这种神经网络与围棋空间的适应性,是之前人们没有想到的,因为人自己感觉很困难,没料到神经网络学习起来美滋滋。
AlphaGo Zero能从零开始训练成功,也是因为围棋的绝对客观性。围棋规则如此自洽,不需要人类干预,就能很容易地自我对弈出结果,直接解决了“学习样本”这个大问题。人工智能机器学习碰上的很大问题就是需要海量样本,而实际生活中有时只有少量样本,有时需要人工标注很麻烦。
围棋的对局天然在那了,AlphaGo Zero的任务就是找到合适的学习方法,没有样本的问题。而人类既无法自我产生海量对局,也无法像AI那样目标明确地快速改进自己的脑神经,单位时间学习效率被AI完全碾压。所以围棋是更适合AI去学习的游戏。人类的学习方法也许还是适合人的,但AI学习方法更强。
对于围棋这么自然而且绝对客观的游戏,消除人类的影响应该从哲学上来说是有深度的想法。从围棋规则来看,日韩规则对AI简直是不可理解,甚至无法定义,未来肯定会消亡。而人类的棋谱是客观的,但对棋谱的解读是主观的。主观的东西就可能出错,这要非常小心。
对于人类的知识体系也是如此。客观世界的运行是与人无关的,人对客观世界的解读就是主观的,很可能带入了错误的东西。所以,有时需要返回到客观世界进行本原观察,而不是在错误的知识体系上进入所谓的“推理与搜索”。客观上不成立,什么都完了。经济学道理写得再雄辩,实践中失败了就不行。
另一方面,也不要片面强调说人类知识没用,还不如零知识。实际上Master与AlphaGo Zero的差距从算法层面看,并不太大。二者300分的等级差距,也许不是Master开始学了人类棋谱带来的,也许是更精细的网络架构、训练过程的小细节之类的影响。Master其实找到办法跳出了人类知识的陷阱。
因此,可以说人类知识可能存在问题,但不要说学了人类知识就没法到高境界。意识到旧知识体系的问题,作出突破就可以了。而且人类没法和机器比,不可能真从零知识开始疯狂自己下,没那个体力。现实的选择只有学习前辈的经验。也许AlphaGo的意义是说,要有一个知识体系,这个知识体系可以是自己学出来并检验的,也可以是Master那样借鉴了别人的,但要接受实践检验,也要敢于怀疑突破成见。
四。AlphaGo Zero的实战表现
虽然AlphaGo Zero完全与人类棋谱无关了,但是也许会让棋手们欣慰的是,它下得其实很像人。训练没几个小时就下得非常像人了,也是从角上开始,这方面的判断和人是一致的。
而且它甚至比Master还要像人类棋手,显得比较正义。Master不知道为什么喜欢出怪异的手段,棋谱极为难懂,对人类而言更为痛苦,打又打不过,看也看不懂。AlphaGo Zero对Master的棋谱结果是19:1,感觉上AlphaGo Zero战胜Master的招数不是以怪制怪,而是用正招去应付,然后Master的强招碰上正义的力量就失败了。而人类对Master应错了,就输了。也许是因为,Master训练到后来,为了提高胜率走上了剑走偏锋的路线,出怪招打败之前的版本,而同一版本的黑白是同等实力,以怪对怪正好实力相当,维持了半目胜负。碰上AlphaGo Zero就失去了这种平衡,被正义的招数镇压。
图为AlphaGo Zero执黑对Master。Master气势汹汹54位飞,要吃掉黑三子。在Master与人类棋手的计算中,以及解说的这盘棋的绝艺看来(腾讯围棋经常有绝艺配合人类棋手解说棋局的节目),黑这三子应该是被吃了,要考虑弃子。但是AlphaGo Zero不这么认为。
黑棋AlphaGo Zero在左下角将白棋做成了打劫杀。遭此打击,Master就此陷入被动。这说明Master的计算也不一定毫无破绽,只是碰上算得更深的才被抓住。这个计算手数很长,出现错误也可以理解。这也说明Master以及AlphaGo Zero从算法原理看,都可能会被抓住计算错误,仍然有进步空间。一度我被Master的极限对局吓住了,以为围棋的终极奥义可能就是这种看不懂的死掐。
AlphaGo Zero执白对Master。这是双方对局的常见局面,白AlphaGo Zero捞足了实地,Master的中央模样像纸糊的一样被打破,败下阵来。

AlphaGo Zero自战。胜率落后的黑用129的手筋撑住了局势,但最后还是胜率越来越低失败了。
应该说AlphaGo Zero的棋谱还是较为自然的,虽然中盘显然很复杂,但不像Master那样完全看不懂心生恐惧。对于人类棋手来说,AlphaGo Zero会更为亲切,它就像一个最高水平的人类棋手,下得是意图可以说清楚的棋,只是永远正确,不像人类低手这错那错。而Master的自战谱就显得不可理解,蛮不讲理,动不动就搞事,撑得很满步步惊心搞极限对局,人类看得很晕。
围棋AI应该还是在发展过程中,自我对弈容易显得较死劲,实力有差距就会显得一方潇洒自然。围棋的状态空间还很大,应该还能有更厉害的版本一级级发展出来,就像国际象棋AI仍然在不断进步。
当然对Master以及AlphaGo Zero的棋谱,需要人类高手们配合AI的后台数据来解读。AlphaGo Zero这个不需要人类知识的AI棋手,再次给人类提供了不同风格的棋谱,让棋坛越来越精彩。而且Deepmind的这篇论文提供了优美简洁的开发方法,更容易模仿成功,会有越来越多高水平的AI取得突破。
[本文来自微信公众号“棋道经纬”]
作者: cateyes 时间: 2017-12-13 17:57
标题: LeCun:不要夸大AlphaGo
http://www.sohu.com/a/200607819_610300
LeCun:不要夸大AlphaGo
2017-10-27 15:28 安妮 编译整理
近日,深度学习领军人物、卷积神经网络的创作者之一Yann LeCun接受了外媒采访。作为Facebook人工智能研究院(FAIR)的院长,LeCun表示距离AI的智力水平超过一名人类婴儿还有很长一段时间。
“如果媒体在报道AI时不用终结者的配图,我会很高兴。”LeCun表示。
如果一个学术大牛表示目前离超级人工智能还远得很,我们是不是应该听听他的想法。对此,The Verge专访了LeCun,量子位将对话实录编译整理如下:
问:最近Facebook机器人“创造了自己语言”的新闻报道火热,其中有很多与实际研究不符的错误理解。对比过去几年,你觉得这类报道变多了还是变少了?
LeCun:少了,媒体人对要讲的故事更了解了。过去你会看到无终结者不AI的情况出现,媒体100%会在报道中插入终结者的配图……现在这种状况只会偶尔发生,是好事。
问:当这种错误报道出现时,你想对公众说什么?
LeCun:我在公开演讲时反复提到,我们离创造真正的智能机器还很远。现在你能看到所有AI的本领——自动驾驶汽车也好,医学影像中的落地也罢,即使是AlphaGo在围棋比赛中拿到世界第一——这些都是非常窄层面上的智能,是在某些可以大量收集数据情况中为了特定功能专门训练的。
我不是想将DeepMind在AlphaGo上的研究影响往小了说,而认为是人们将AlphaGo的发展解读为机器智力发展的重要过程是不妥的。这两者完全不是一回事。
不是有一台在围棋上能打败人类的机器,就会有智能机器人满街跑,这是两个完全独立的问题,前者对后者可能几乎没有影响。
在这里我想再次重申,距离机器像人和动物一样了解世界还有很长时间。是的,在某些方面机器确实表现超人,但在一般智力因素上,机器的“智商”甚至赶不上一只老鼠。所以很多人过早考虑了某些问题……
当然,也并不是说我们不应该考虑,但至少从当前到发展中期水平时人类是安全的。我承认AI确实存在危险,但他们不是终结者啊!╮(╯▽╰)╭
问:DeepMind在AlphaGo中创造的算法也可以应用到其他科学研究中,比如蛋白质折叠和药物研究。你认为在其他地方应用这种研究容易吗?
LeCun: AlphaGo中用的是增强学习。在游戏中,这适用于有少量离散动作的情况。因为它需要很多,很多,很多的试验来运行复杂的东西,所以比较有效。
AlphaGo Zero在几天内下了数百万盘围棋,可能比人类在发明围棋以来的大师下得还要多。因为围棋是个非常简单的环境,可以在多台计算机上以每秒数千帧的速度模拟它,所以行得通……但在现实世界中,你无法以比实时更快的速度运行真实的世界,所以行不通。
要想摆脱这种局面,唯一的方法就是让机器通过学习建立内部的世界模型,这样就能超过现实提前预测世界。目前我们缺乏的就在于如何教机器构建世界模型。
比如说学开车,人类有足够好的系统模型,就算是初次开车,也知道我们需要在路上驾驶汽车,不要让车坠入悬崖或者撞树。
如果我们在模拟器中只用增强学习训练汽车,那么在撞树4万次之后它才知道这是错误行为。所以,声称只用强化学习就能提升机器智力是错误的。
△Facebook在美国普林维尔的数据中心
问:你是否认为,AI缺少超越它目前局限的基本工具?AI先驱Hinton最近提到这段话,表示当前领域内太过依赖“把它全部扔掉,然后重新开始”的方法。
LeCun: 我认为Hinton有些过度解读了,不过我完全认可“我们需要更多基础的AI研究”。例如,Hinton喜欢的模型之一是他在1985年提出的玻尔兹曼机(Boltzmann machine)。他认为这个算法很好,但实际应用中并不是很有效。
我们想找到兼具有玻尔兹曼机的简单和反向传播的效率的机器。这就是Bengio、Geoff、我和很多人在21世纪初重新开始深度学习研究以来做的事。
让我们有点小惊讶的是,最后在实践中反向传播和深度网络配合得很好。
问:所以,考虑到AI研究中的大变革,你认为在短期内什么对消费者来说是最重要的?
LeCun: 我认为虚拟助手是件大事。现在的虚拟助手完全是照本宣科,尽管在客服等场景下有用,但这让创造机器人这事乏味、昂贵且易夭折。
△Facebook在虚拟助手的研究上投入了大量精力,但还远远落后于Alexa等竞争对手
下一步的重点是让系统有更多的学习能力,也是我们在Facebook的研究方向。想象一下你有一台可以读取长文本的机器,读完后能回答任何相关问题,是不是个很实用的功能呢?
到此程度的重点是机器和人有同样的背景知识,也就是常识。但除非我们能找到让机器通过观察了解世界是如何运作的方法,否则无法实现这个想法。这里指的观察是仅仅通过看书或者看视频了解整个世界。
这是未来几年的关键性挑战,我称之为预测学习,有人称为无监督学习。
接下来的几年,随着虚拟助手越来越实用,越来越不让人失望,这些任务将有持续进展。机器将有更多常识去做设计师编写的程序之外的事情,这也是Facebook非常感兴趣的内容。
作者: cateyes 时间: 2018-6-22 19:10
标题: 田渊栋:AI还不是围棋之神 但终将造福全人类
http://sports.sina.com.cn/go/2018-06-22/doc-ihefphqm6601442.shtml
田渊栋:AI还不是围棋之神 但终将造福全人类
2018年06月22日 15:44 新浪体育
 AI科学家田渊栋 2018腾讯世界人工智能围棋大赛的举办,为全世界的开发者提供了面对面交流探讨的平台。借此机会,我们亦有幸请到了全世界最顶级人工智能科学家,作为访谈对象。
AI科学家田渊栋 2018腾讯世界人工智能围棋大赛的举办,为全世界的开发者提供了面对面交流探讨的平台。借此机会,我们亦有幸请到了全世界最顶级人工智能科学家,作为访谈对象。
从谷歌的无人车组到Facebook的人工智能实验室(FAIR),一度是FAIR唯一能打中文的全职研究员的田渊栋博士,带领一个团队重复了AlphaGoZero的算法,在一个月前发布了ELF OpenGo,并宣布开源。围棋AI的格局也因此发生了天翻地覆的变化。
然而取得如此成就的田先生,却在访谈的一开始就表示“原则上本次参赛我们倒数第一”。看完本期访谈后,相信您的收获将不仅限于围棋,更会对人工智能拥有更深刻的认识。
——野狐小编:田博士您好,很荣幸能够借这次腾讯世界人工智能围棋大赛的机会,聆听世界级人工智能大牛的传道解惑。早在2015年您便从事过围棋AI的开发,并且比谷歌早三个月发表文章,证明了用深度学习破解围棋的可行性。
一个多月前您的ELF OpenGo再次震惊围棋界。经广泛评测,目前公认ELF OpenGo是普通人能接触到的最强AI。可能会有人下意识认为这是“三年不鸣,一鸣惊人”,事实上ELF OpenGo达到如此水平仅用了不到4个月时间。可否向棋迷们分享开发过程和感想?
——田渊栋:其实并没有“三年不鸣,一鸣惊人”,作为研究员肯定还是要每隔一段时间鸣一次的。在DarkForest这个项目在2016年4月停止之后,这两年还是做了很多事情,包括设计Doom AI,做深度学习梯度下降算法的理论分析,ELF框架的提出及在NIPS大会上的演讲,House3D环境的发布及算法设计,还有这次ELF的改进和OpenGo,等等。两年可以做很多事的,只是大部分都没有涉及到围棋,所以棋迷们可能不知道我们的工作。
其实在去年10月AlphaGoZero文章出来之后我就想动手,不过那时正是赶会议论文及开会的时间,忙的不可开交,只能看不能动手的感觉是很不爽的。ELF OpenGo大约在今年1月才开始做,这个项目的目的并不是只为了围棋,而是作为ELF这个框架的一个测试和推广。去年ELF出来之后,尽管我在各种地方做了大量的演讲,推广仍不是很顺利(毕竟是C++代码,写得人比较少,而且第一版的代码组织也不太行),自然地我就想到需要一个具体应用,正好AlphaGoZero出来,配上以前的围棋代码,再合适不过了。于是我就花一周重写了一遍ELF的核心,增加了分布式系统的部分,然后按照论文把系统做了一遍。基本上二月中就可以跑了,接下来就是比较痛苦的调参和找bug的过程,一直到三月下旬我们才看到希望,然后才有了CGOS上的王朝系列和美国总统系列,和最后五月份的发布版。
 田渊栋与李喆
田渊栋与李喆
——野狐小编:可否进一步透露一下达到这样一个水平,背后调动的硬件资源,是一个怎样的概念?
——田渊栋:我们用了两千块V100的显卡训练两到三周。两千块卡其实还好,没有特别多。对比谷歌,我们的资源还是比较有限的。当然这个对于大部分人来说还不能接触到,不过我相信随着算法的改进和硬件的进步,说不定过几年每位棋迷都可以亲手训练了。
——野狐小编:您认为借助CNN(卷积神经网络),通过堆砌资源,或者资源+时间的方式,能否帮助我们触摸到想象中的“围棋之神”境界?
——田渊栋:不觉得如此。首先围棋状态还是太多,现在探索到的只是很小一部分。大家可以做个算数,四百九十万局乘上每局平均250步,能够覆盖多少围棋的局面,而所有可能的围棋局面又有多少,就知道拿“沧海一粟”这个成语来形容,实在是太无力了。另外人类在学围棋的时候会形成很多概念,但目前CNN还做不到,而且通过堆砌资源可能永远做不到。这个是人类智能优于CNN的地方,也是算法可以继续改进的地方。
——野狐小编:那么除了围棋,其他一切领域是否都有可能通过这种方式取得突破。
——田渊栋:AlphaGoZero系列算法虽然通用,但远不是能解决一切问题的灵丹妙药。概念上来说它需要一个完美及快速的模拟环境,还需要神经网络与具体问题相容。去年我写博客的时候,能看到它的问题;在复现完这个算法之后,我们知道得要多得多,也对它的局限性有更深刻的认识。总的来说,对AI不能过于乐观,想要让它在一切领域都有突破,还早,需要大家共同努力。

——野狐小编:ELF OpenGo宣布开源,对正在做AI、做围棋AI以及从事围棋相关行业的人群,带来了强烈而迥异的震动。耗费如此昂贵的资源让ELF OpenGo达到这样一个水平,又免费提供给所以人借鉴使用,能否向我们科普这种“极客”范儿十足的做法的出发点?
——田渊栋:这些资源确实不便宜,但“昂贵”实在谈不上,应该没有北京一套房贵,所需的人力和耗时也并不多。一开始一两个月基本上都是我一个人在推动,等到看到了希望,就自然会有更多的同事加入。
做这个项目的目的,一是去了解DeepMind提出的AlphaGoZero及AlphaZero算法为什么能工作,有什么优缺点,如何去改进;二是借此机会完善和推广我们的ELF平台,以后可以用于其它目的;最后是借此磨练项目组,这次参与的组员有些新人,一起做成一个项目,对大家都是有好处的。
至于开源是我们一向的方针,科研要服务全人类,这是科研的最终目的。我相信就算没有我们,像LeelaZero也会逐渐达到目前OpenGo的水平,甚至更高(他们现在应该很厉害了)。
——野狐小编:宣布开源后,ELF在围棋上的研究是继续进行,还是再度终止?未来打算探索哪些领域?
——田渊栋:ELF框架会继续改进,下一步计划还在讨论中,目前暂不透露。两年前DarkForest终止主要是因为当时科研上再做一个单独的围棋AI价值不大了。这次是用通用算法训练出来的,所以会继续思考其它各种想法,围棋模型作为一个明确客观的测试方案,当然会尝试,但是不一定只用在围棋上,也不一定以性能为导向。

——野狐小编:如果将来,人们发现一种深度学习以外的算法,也能适用于围棋,甚至比深度学习的效果更佳(效率或者高度),围棋会再次吸引人工智能领域的科学家们开发新一代AI么?
——田渊栋:那是必然的。职业棋手们一辈子没有下过几百万局棋,却达到了很高的水准,并且能解释每一步的下法,对围棋有自己的世界观和方法论。这些都是人工智能目前完全达不到的,也是作为科学家的我们一直努力研究的目标。如果能只用几万局自对弈棋谱训练出强AI,或者让一个挂在网上的小白AI通过和对手对下来成长,或者设计出能够抽象出围棋各种基本概念的AI,将会是很有意思的事情。
——野狐小编:ELF这三个字母对于棋界即便不是人尽皆知,也即将在人尽皆知的路上。然而绝大多数棋迷对“ELF”的认知,还仅仅停留在一款单卡碾压人类高手的围棋AI上,并不知道ELF是一个开源游戏平台。身为开发者,您在命名时赋予了“ELF”非常浪漫的想象和希冀,可否为大家介绍一下作为开源游戏平台的“ELF”?(注:ELF原名为LigthELF,意为“光之精灵”)
——田渊栋:ELF是一个通用的强化学习训练平台,第一版在去年六月的时候发布,当时带了一个微缩版的即时战略游戏(MiniRTS),可以用强化学习训练AI打即时战略游戏,这里是一些演示视频(http://yuandong-tian.com/minirts_v1/minirts_video.html),后来我们在上面做了大量改进,这次随OpenGo发布的是第二版的ELF还有分布式训练代码,这些都是通用的,和围棋无关,之后ELF还会继续改进,名字很浪漫,不过脚印还是要一步一步走的。

——野狐小编:我想棋迷和参赛者,都是以看待绝顶高手的眼光,来评价本次ELF团队的参赛的,您对于本次参赛抱有怎样的预期?
——田渊栋:首先这次我们还是以团队身份,作为基线算法(baseline)参赛的,以推广我们的OpenGo。我们已经开源,所以原则上我们是倒数第一。
——野狐小编:倒数第一……对我们围棋迷来说,您和您的ELF OpenGo是宛如世外高人一般的存在。“倒数第一”这个说法会不会让其他参赛者们亚历山大
——田渊栋:我们开源后一直鼓励大家使用,这一个半月以来我相信很多团队已经找到改进的方案,比如说加一些额外的条件防止出现征子bug,这些都会让OpenGo变得更强。这次参赛,能让大家用我们的平台,那就是达到目的了。团队还有很多任务要完成,我们不会为这次比赛的胜负花太多力气在上面,所以我们并不期望OpenGo可以获得很高的名次。当然啦,我们还是希望它能赢。

——野狐小编:围棋进入AI时代以来,棋迷与棋手们诞生过许多有趣的、神化AI的说法。比方说公众目前普遍将AI看作“围棋之神”,还有人认为其实两年前第一次人机战时,AI已经拥有让人类三子的实力。有些人连CNN(卷积神经网络)和RNN(循环神经网络)都分不清,却深信AI可以解决一切问题,对此您怎么看待?AI对围棋、乃至对当前人类社会意味着什么?
——田渊栋:对于棋手们来说,围棋AI已经可以让他们大幅度提高平时训练的效率,对于棋迷们来说,有一个顶尖高手时刻陪着自己下棋,并且能不停指出落子的问题所在,这种感觉可能是之前从未体验过的。《棋魂》里面小光和佐为的梦幻组合,现在已经实现了。虽然我个人认为AI离围棋之神还有距离的,但可以确定的是,将来AI会成为进一步提高大家效率的必要工具,甚至成为水和空气那样的必需品,谁能用得好,谁就可以变得更强。至于AI将来能不能解决一切问题,现在回答这个问题还为时过早,还需要大家的努力。
——野狐小编:在您的心目中,围棋的未来是怎样的?它的意义、价值该如何体现?
——田渊栋:我自己围棋大概是18k的水平,所以这个问题不好回答。围棋的未来大概可以参照现在的国象,大家用软件训练及评测,会有更多的人成为爱好者参与进来,会有更多的人自学成材,会有更多人发现新的着法。我想作为一个有着三千年历史、浓厚中国文化底蕴和无穷变化的游戏,围棋可能会变得更加繁荣吧。
(责编:樊璐璐)
作者: cateyes 时间: 2018-8-5 07:28
本帖最后由 cateyes 于 2018-8-5 07:29 编辑
http://sports.sina.com.cn/go/2018-07-31/doc-ihhacrce3966950.shtml
星阵围棋:不退让棋风坚持不变 绝艺达到Master 2018年07月31日 18:17 新浪体育

星阵团队
7月31日下午,2018腾讯世界人工智能围棋大赛颁奖仪式在中国棋院举行,星阵围棋获得亚军。赛后,新浪棋牌对星阵围棋董事长金涬进行了采访。
新浪棋牌:决赛结果0:7失利,这和您预想到的结果有差异吗?
金涬:总体发挥稳定,半决赛期间和ELF我们发挥的稍好一些吧,跟绝艺决赛,考虑到绝艺的超强实力,绝艺对决赛很重视,上了最新版本,资源也是最高配置,我们在模型上和配置上和绝艺应该说都有差异。最终的结果虽然比较遗憾,但是我们也尽力了,毕竟各方面都有差距,我们以后继续努力吧。
新浪棋牌:本次AI大赛中,在复赛阶段星阵经常会出现“秒下”的情况,这是什么情况呢?
金涬:在对方思考的时候它也在思考。我们会假设某个分枝我们已经思考的比较充分了,就不用再想了。
新浪棋牌:就像人类利用对手时间思考?
金涬:对,就像人类利用对手时间思考一样。
新浪棋牌:星阵还会坚持“不退让围棋”的棋风吗?
金涬:这个是我们和论文架构不一样的东西,我们还会用这个架构去发展,所以这个风格还会保持。我们的架构可能相对灵活一些,我们去训练让先、或者无贴目、乃至小棋盘……这些都可能去发展。
新浪棋牌:您能否评估下,现在的星阵和AlphaGo各版本相比,实力在哪个阶段?
金涬:我们实力是在……这个确实很难讲,因为它不出来,我们也很难去评估。你们是不是也问绝艺这个问题了?很多人对这个问题也很关注,是很难讲,绝艺也很强。因为Master和AlphaGo Zero有300多分的差距,感觉达到Master,和Zero不远了。
新浪棋牌:星阵围棋的发展方向能再介绍下吗?
金涬:我们就先把围棋这块做好,另外我们算是做人工智能的团队,希望这个算法在其他领域其他行业有结合点,做一些人工智能方面的AI项目。
(胡波)
作者: cateyes 时间: 2018-8-5 07:33
http://sports.sina.com.cn/go/2018-07-31/doc-ihhacrce3813546.shtml
绝艺:站在巨人肩膀上 未来还会坚持围棋AI研发 2018年07月31日 17:53 新浪体育

绝艺团队
7月31日下午,2018腾讯世界人工智能围棋大赛颁奖仪式在中国棋院举行,绝艺获得冠军。赛后,新浪棋牌对绝艺团队人员进行了采访。
新浪棋牌:恭喜夺冠!绝艺再本次世界人工智能围棋大赛可以说是一骑绝尘,毫无悬念夺冠,身为绝艺团队的一团,您现在的心情如何?
绝艺团队:心里一块石头落了地。特别是很多对手复赛时候比预赛时强很多,当时很有压力。
新浪棋牌:现在AI经常会出现征子问题,绝艺复赛有一盘棋输给星阵,是出现了征子BUG了吗?有没有解决这个问题。
绝艺团队:这是绝艺从预赛到复赛下了很多盘棋,我们也在尝试不同的版本,那一盘刚好是那个版本有问题,触发了问题。在复赛初期出现了这个问题,是坏事也可能是好事。在决赛才有更完满的发挥。
新浪棋牌:那你觉得现在的绝艺和AlphaGo谁强呢?
比如和Master以及AlphaGo Zero相比?
绝艺团队:我个人是觉得,绝艺和AlphaGo通过现有资料是无法对比的,只有通过真正下过棋才能对比。(在问到下一个问题时又进行了补充)我再补充一下,它们谁强只有下过才知道,即使以后有人工智能超过AlphaGo,那也不能改变它的地位。对人工智能围棋的开创作用,AlphaGo还是最大的,它的影响力是无法企及的,我们可以说是“站在巨人的肩膀上”。
新浪棋牌:听说现在野狐围棋开通了复盘功能,绝艺也能给普通棋迷复盘了吗?
绝艺团队:腾讯围棋的用户很多,围棋复盘功能主要是针对业余爱好者的,我们只能降低用算量,来满足更多的用户使用绝艺复盘功能。
新浪棋牌:能否给我们介绍一下具体情况。
绝艺团队:绝艺复盘主要有两个功能,一个是胜率曲线,还有一个是针对每一步给出变化图。胜率曲线的每一步其实只做了神经网络的预测,就是价值网络的胜率,并没有做树搜索;而变化图只做了1600次的树搜索,这个计算量水平大概相当于业余顶尖到职业初级,就是水平不是非常高,所以目标用户是针对水平较低的爱好者,而不是职业棋手;职业棋手的话就用国家队的那个专用训练AI。
新浪棋牌:能否给我们介绍下未来绝艺的发展之路。
绝艺团队:未来绝艺还会坚持围棋AI的研发,进一步会做优化,除了实力的不断提升,我们还会尝试一些新的东西,比如开发让子棋。AlphaGo Zero的算法,是到目前为止分先规则下最强的下法,但是它很不适合下让子棋,我们看到的情况是分先越厉害让子越差,我们要在这个算法的基础上做一些修改,使之适合于让子棋。另外一方面,腾讯野狐去做更多的运算工作,这个可能需要和他们一起去做,我们提供技术支持。
(胡波)
作者: hred9D 时间: 2018-8-10 21:34
以胜负结果论英雄吧,AlphaZero就是强,说他bug,只是猜测了
作者: cateyes 时间: 2019-2-14 18:08
本帖最后由 cateyes 于 2019-2-14 18:09 编辑
围棋AI ELF OpenGo全面开源 田渊栋揭秘训练过程 2019年02月14日 16:25 新浪体育
来源:量子位 现在,随时、随地、随心情,你都能和国际顶级围棋AI对战交流一局了。
最近,Facebook的围棋AI ELF OpenGo全面开源,下载ELF OpenGo最终版本模型,人人都能与ELF OpenGo下棋。
对了,不要被ELF OpenGo“超能力”般的棋艺惊叹到,不仅是你,连韩国棋院的专业围棋选手也被打败了。在与金志锡,申真谞,朴永训及崔哲瀚四位专业棋手对战时,ELF OpenGo以20:0的成绩大赢特赢。
甚至围棋AI界小有名气的前辈Leela Zero,也以18:980的成绩被ELF OpenGo远远甩在身后。
今天,Facebook公布了ELF OpenGo的研究论文,复现了AlphaGo Zero和AlphaZero,还详细揭秘了ELF OpenGo的训练细节,附带了一系列开源地址。
在今天刚发布的论文ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero中,Facebook研究人员全面披露了ELF OpenGo的训练过程。

ELF OpenGo是去年诞生的。当时,Facebook改进了自己面向游戏的机器学习框架ELF,在上面重新实现了DeepMind的AlphaGoZero及AlphaZero的算法,得到了这个围棋AI ELF OpenGo。
论文显示,训练过程大部分遵循了AlphaZero的训练过程。
和AlphaZero用5000个自我对弈的TPU和64个训练TPU不同,整个训练过程共用了2000块英伟达GPU,型号均为英伟达Tesla V100 GPU,内存为16GB,总共训练了15天。
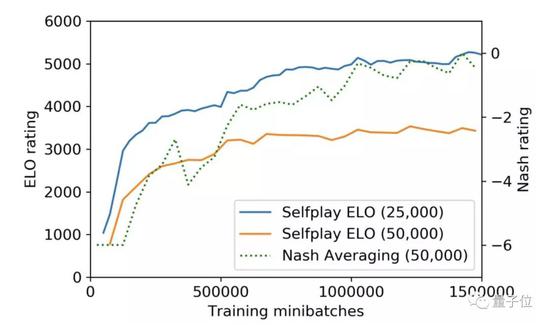
研究人员还应用了ELF OpenGo,完成了另外三方面突破。
一方面,为ELF OpenGo训练处一个棋艺超越人类的模型。
研究人员开发了一个类似AlphaZero的软件,在上面用2000块GPU连续训练了9天后,这个20个区块的模型的表现已经超过了人类水平。
随后,研究人员提供了一些预训练模型、代码和2000万局自我对弈的训练轨迹数据集进行训练。
第二方面,研究人员提供了模型在训练过程中的行为分析:
在训练过程中,研究人员观察到,ELF OpenGo与其他模型相比,水平变化比较大,即使学习率稳定,棋力也会上下浮动。
另外,模型需要依靠前瞻性来决定下一步棋怎么下时,模型学习速度较慢,学习难度很大。
除此之外,研究人员还在探索了在游戏的不同阶段AI学会高质量的棋法的速度。
第三方面,研究人员进行了Mextensive ablation实验,学习AlphaZero风格算法的属性,对比了ELF OpenGo与AlphaGo Zero与AlphaZero的训练过程。
研究人员发现,对于最终模型而言,对局中加倍rollout水平大约提升200 ELO,AI的发挥会受到模型容量的限制。
目前,ELF OpenGo的论文、模型、实现代码、自我对弈数据集和与人类对弈记录等已经全部开放,地址可到文末寻找。
明星团队
这篇论文来自Facebook人工智能研究所(FAIR),一作国内机器学习圈里一个熟悉的名字,田渊栋。
田渊栋从卡内基梅隆大学(CMU)毕业后,田渊栋奔赴谷歌无人车项目组,随后跳槽转向Facebook人工智能研究所。Facebook围棋AI Darkforest的相关研究,负责人和论文一作也是田渊栋。

△ 田渊栋本人
田渊栋也一直活跃在知乎,是人工智能、深度学习话题的优秀回答者,是知乎er心中的大神。
去年,田渊栋回顾自己近几年的工作感悟和学习生涯的文章《博士五年之后五年的总结》,曾成为圈内的爆款文章,不少网友再次被圈粉,大呼醍醐灌顶。
论文二作Jerry Ma也同样为华裔,其Facebook介绍显示,2018年,Jerry Ma刚刚本课毕业,获得哈佛大学经济学和古典文学学士双学位。目前担任Facebook研究工程负责人。

△ Jerry Ma 年纪不大,责任不小。
传送门
GitHub地址:
https://github.com/pytorch/ELF
论文地址 :
https://arxiv.org/abs/1902.04522v1
Facebook博客介绍:
https://ai.facebook.com/blog/open-sourcing-new-elf-opengo-bot-and-go-research/
ELF OpenGo官网:
https://facebook.ai/developers/tools/elf-opengo
另外,如果你自带Windows系统的电脑,还可以下载这个软件,在线下棋。下载地址:
https://dl.fbaipublicfiles.com/elfopengo/play/play_opengo_v2.zip
作者: jcjcw3 时间: 2019-2-14 20:07
谢谢分享!
作者: cateyes 时间: 2019-5-2 16:35
http://sports.sina.com.cn/go/2019-05-01/doc-ihvhiewr9342802.shtml
星阵让2子4-0女子顶尖 金涬博士访谈(附实录)2019年05月01日 17:02 新浪体育综合
 比赛现场
比赛现场
中国智力运动网讯 4月30日,“博思杯”2019世界人工智能围棋大赛收官,在最后一天进行的人机对抗赛中,本次人工智能大赛冠军星阵围棋让2子迎战芮乃伟、王晨星、李赫、曹成亚取得全胜。赛后星阵团队金涬博士接受了采访。
以下是金涬博士采访实录:
问:赛前棋迷朋友们对星阵的期望很高,认为星阵的水平远超过其他参赛AI,但是在预赛第一轮,星阵却爆冷输给了leelaZero,星阵此次比赛首战失利的原因是什么?
答:本次预赛采用30分钟包干赛制,需要很好的时间分配策略。星阵在预赛第一盘有一定失误。这盘棋用时策略设置的太快了,导致我们下到第113手问题手时用时不足3分钟,思考还不够充分,没有考虑到对手的一些妙手。走出问题手时发现不对已经来不及了。不合理的时间分配策略使星阵相当于只用了几分之一的算力进行比赛。调整了用时策略之后,星阵的棋力有了明显的提高,在后面的比赛中发挥稳定。
问:这次世界大赛的整体水平与过去的几届有何不同?与一年前相比,星阵进步了多少?围棋AI水平的上升空间还有多大?
答:这次世界大赛是星阵参加过的最高水平的AI比赛。参赛的选手的实力都比之前大大提升。其中棋力提升最明显的就是LeelaZero和小爱围棋。比赛前不少其他参赛选手都提出自己的目标是夺冠,说明他们自评超过了前一次围棋AI比赛的冠军水平。
星阵在这一年中棋力有了非常大的提升,星阵能连续夺冠的原因是比对手的提升更快。围棋AI已经远超过人类水平,但是AI对围棋的理解也只是围棋知识的一小部分,围棋还远远没有被破解,进步提升的空间仍然是巨大的。但是,仅靠学习已有的技术或复制AlphaGo论文工作,仍然会遇到瓶颈。星阵团队努力从算法和模型层面取得突破性进展,以进一步提高围棋AI的水平。
问:这次比赛留下了很多精彩的棋谱,过程中星阵下出了开源软件未预料到的惊艳手段,如半决赛第2局183、187,决赛第3局145、147等,这种带有个性化棋风特点的招法很符合人类的审美观,请问是如何形成的?
答:这种妙手是星阵在自我进化的过程中自然形成的,星阵在深度学习模型和算法上有一定的创新性工作,这使得星阵具有准确的价值和目数评估网络和较强的策略网络。在星阵眼中,这种妙手是通向更高胜率和更多目数的一条好路径,这使得星阵更容易挖掘出这样的妙手。
问:星阵这次让两子的人机赛表现不错,您认为目前顶级人机之间的差距有多大?
答:人机对战一直以来都是大家关心和关注的话题,首先非常感谢主办方提供这次机会,举办这次成功的比赛。 最近几年,在AlphaGo的带动下,围棋AI的水平提高很大。与此同时,顶尖人类职业棋手也使用AI进行训练,学习提高了棋力,不断缩小和AI之间的差距。可以说人类和AI都在不断的快速进步。人类棋手和AI之间的差距未必会像想象中那样越拉越大,具体有多大的差距,只能靠比赛结果来验证。
问:据说星阵下的是不退让围棋,但比赛中似乎也偶有退让,是怎么回事?
答:星阵可以下完全不退让的围棋,在去年的对人类顶尖高手的让先表演赛中使用过这种下法。但完全不退让的下法有时会因为奋力拼搏承担很大风险,例如去年星阵让先对谢科的棋,星阵在领先的情况下希望扩大战果,但由于误算被翻盘。这是一个度的把握。不退让围棋可以更快的扩大优势,也可以在落后的时候咬住局面努力缩小差距,因而可以增大获胜的机会。但完全不退让反而会降低胜率。因此,参加高水平AI比赛时使用带有不退让下法的星阵,但不是100%完全不退让。
问:有网友说星阵使用超算参加比赛,使用开源围棋AI的棋谱进行训练,这个说法符合事实吗?
答:很多网友看到星阵经常秒拍,以为星阵算力非常强,使用了超算。事实上,这是一种智能的用时策略,简单的地方秒拍,困难的地方可以长考。星阵没有使用过超算,星阵棋力提升的主要还是靠深度学习模型和算法上的优化提升。事实上,当算力资源达到一定程度的情况下,单纯提高对弈时使用的算力对棋力提升并不明显,很多棋局方向的选择,都要靠模型的准确判断,而不是靠计算。另一方面超算的架构也并不适合围棋AI。
星阵没有使用过任何开源围棋AI的棋谱进行训练,因为不退让围棋的训练方法与AlphaGo架构有所不同,AlphaGo架构的开源软件的棋谱不能直接使用。星阵早期主要使用人类棋谱,目前主要使用星阵自对弈棋谱进行训练。
问:星阵可以提供独特的目数评估,这对参加比赛有帮助吗?
答:目数评估使得星阵可以从胜率和目数两个不同方面评价围棋进程。这种综合的评估方式相比于纯用胜率进行评估具有更高的棋力。此外,目数评估可以让星阵在极大的胜率优势下追求最大目数,下出更精彩的棋局。我们在比赛中使用了这种方式取得了不错的效果。
问:星阵团队在围棋上取得了很不错的成绩,请问星阵的人工智能技术是否能在其他应用领域发挥作用?
答:我们深客科技团队研发星阵围棋,主要是为了验证和研究深度学习和强化学习算法,并将人工智能算法应用到其他领域。
目前,我们正在与合作伙伴一起,积极探索和推进人工智能在围棋以外的应用。包括使用人工智能技术进行风力电场的发电量预测,以及通过精确控制数据中心的空调制冷系统,来做数据中心的智能节电。这些方向都有很好的应用前景。我相信人工智能技术还会在其他更多与人们生活息息相关的领域发挥更大的作用。
作者: 渐渐领悟 时间: 2019-5-2 21:01
必须慢慢品味,今天喝多了,当然不喝多也看不懂
| 欢迎光临 飞扬围棋 (http://bbs.flygo.net/Bbs/) |
Powered by Discuz! X3.2 |





















